[KANS 3기] 컨테이너 격리
들어가며
지난 테라폼 스터디에 이어 이번 주 부터 KANS 스터디를 시작하게 되었습니다!
KANS는 Kubernetes Advanced Networking Study의 줄임말로 쿠버네티스 네트워킹에 대한 심도있게 공부하는 스터디입니다.
이번 스터디도 과제할 걱정도 ![]() 되지만 재미있을것 같아 기대됩니다.
되지만 재미있을것 같아 기대됩니다. ![]()
첫 주 스터디도 컨테이너 격리와 리눅스 네트워크에 대해 많은것을 배웠고 이 자리에 정리해보려고 합니다. 이번 스터디도 다들 완주하기를 기도하며 스터디 정리를 시작해 보겠습니다.
도커 소개
도커란 무엇인가?
-
도커(Docker)는 컨테이너(Container)라고 불리는 가상실행 환경을 제공하고, 그 가상환경에서 유용한 어플리케이션을 실행할 수 있게 해주는 오픈소스 플랫폼입니다.
-
컨테이너라는 이름의 기원 컨테이너라는 이름은 배에 화물을 실을때 사용하는 그 컨테이너에서 왔습니다.
 과거에 컨테이너가 발명되기 이전에는 짐의 부피와 모양이 제각각이라서, 화물을 적재하기도 어렵고
파도가 쳐서 배가 흔들릴때 짐이 이리 저리 움직여서 파손되는 경우가 많았습니다.
과거에 컨테이너가 발명되기 이전에는 짐의 부피와 모양이 제각각이라서, 화물을 적재하기도 어렵고
파도가 쳐서 배가 흔들릴때 짐이 이리 저리 움직여서 파손되는 경우가 많았습니다.이 문제를 해결하기 위해 Malcom McLean이라는 분이 발명한것이 직육면체의 바로 컨테이너입니다.
 직육면체이기 때문에 적재가 쉽고, 파도가 치더라도 안정적으로 화물을 운반할 수 있었습니다.
또한 크고 작은 물건도 컨테이너 안에 넣어서 운반할 수 있어서 화물의 종류에 상관없이 효율적으로 운반할 수 있었습니다.
직육면체이기 때문에 적재가 쉽고, 파도가 치더라도 안정적으로 화물을 운반할 수 있었습니다.
또한 크고 작은 물건도 컨테이너 안에 넣어서 운반할 수 있어서 화물의 종류에 상관없이 효율적으로 운반할 수 있었습니다.이 개념을 컴퓨팅에 도입한것이 컨테이너입니다. 기존에는 각 리눅스 버전마다, glibc냐 musl이냐, debian 기반이냐 redhat 기반이냐 등등 프로그램을 배포할때 환경을 맞춰야 하는것이 많았습니다. 그 뿐만아니라 각종 라이브러리들도 설치해야 하고 심지어 프로그램 마다 필요한 라이브러리 버전이 다를때도 있었습니다.
이러한 문제를 해결하기위해 도커라는 컨테이너를 이용한 가상화 기술이 등장하게 되었습니다. 도커 컨테이너 이미지에는 프로그램 실행에 필요한 모든것이 포함되어 있기 때문에 마치 컨테이너에 화물을 싣듯이 프로그램을 배포할 수 있게 되었습니다. 도커의 로고가 컨테이너를 싣고 있는 배를 형상화한것도 이러한 의미에서 나온것입니다.

-
컨테이너 이외에도 가상 머신(Virtual Machine)이라는 기술이 있습니다. 가상 머신은 하이퍼바이저(Hypervisor)를 이용하여 호스트 OS 위에 게스트 OS를 올리는 방식으로 가상화를 구현합니다. 가상 머신은 게스트 OS를 올리기 때문에 무겁습니다. 반면 컨테이너는 호스트 OS의 커널을 공유하기 때문에 가볍습니다.
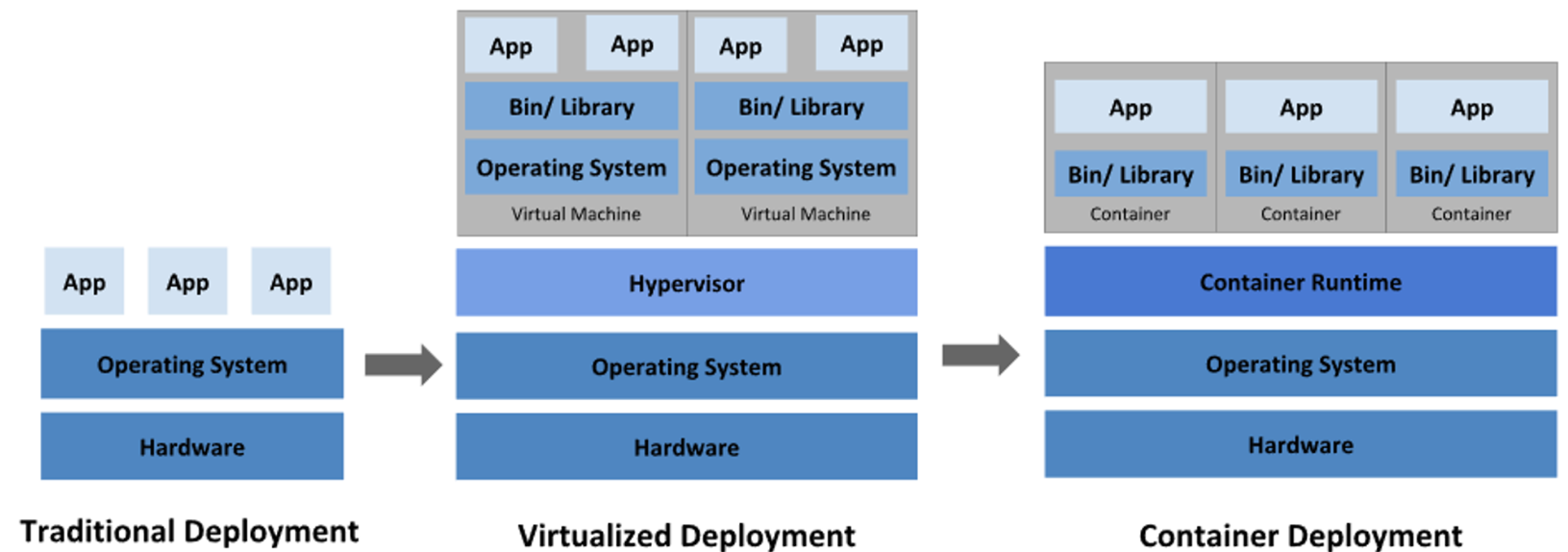
컨테이너와 가상 머신
- 가상머신은 호스트 OS 위에 하이퍼바이저를 두고 하드웨어 일부(또는 전부)를 가상화하고, 그 위에 게스트 OS를 올립니다. 즉, 하드웨어 레벨의 가상화를 지원합니다.
- 컨테이너는 하드웨어 가상화와 게스트 OS 없이, 호스트의 리눅스 커널을 공유하여 바로 프로세스를 실행합니다. 단, 각종 라이브러리와 사용자 환경(User Land)는 컨테이너 단위로 패키징되어 OS 레벨의 가상화를 지원한다 할 수 있습니다.
- 따라서 컨테이너는 가상머신보다 가볍고 빠르며, 낮은 격리(Weak Isolation) 수준을 가집니다.
- 가상머신은 게스트 OS를 올리기 때문에 무겁고 느리지만, 높은 격리(Strong Isolation) 수준을 가집니다.
- 낮은 격리 수준을 보완하기 위해 리눅스의 pivot-root, namespace, cgroup 등의 기능들을 활용함으로써 프로세스 단위의 격리 환경과 리소스 제어를 제공합니다.
- 낮은 격리 수준을 보완하기 위해 리눅스의 pivot-root, namespace, cgroup 등의 기능들을 활용함으로써 프로세스 단위의 격리 환경과 리소스 제어를 제공합니다.
도커 아키텍쳐
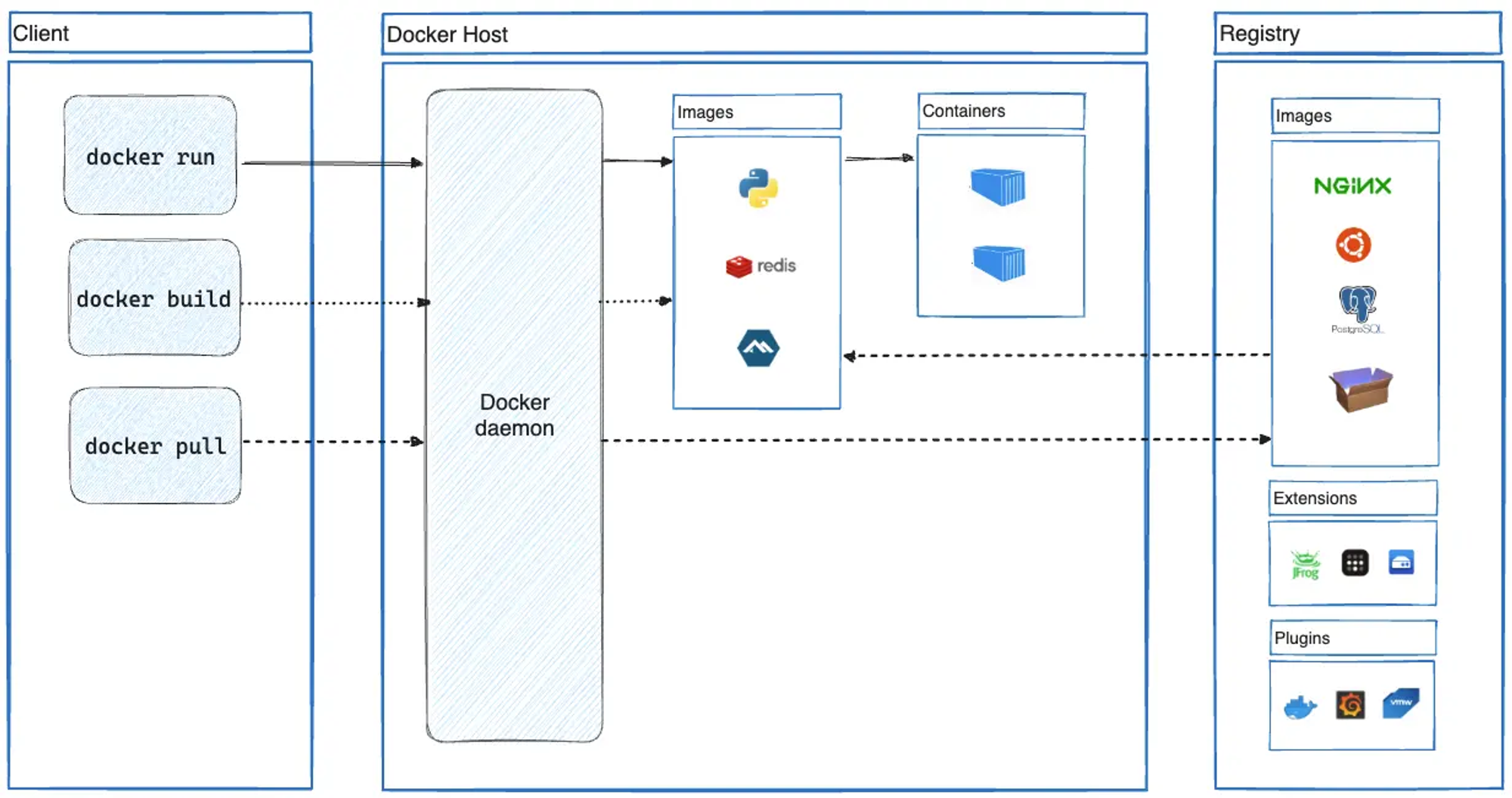 https://docs.docker.com/get-started/overview/#docker-architecture
https://docs.docker.com/get-started/overview/#docker-architecture
도커 기본 사용
도커 설치 및 확인
- 도커 설치
# 방법1. debian 계열 리눅스에서 패키지 매니저로 설치 $ sudo apt-get update $ sudo apt install -y docker.io # 방법2. 공식 사이트에서 설치 $ sudo -i $ curl -fsSL https://get.docker.com | sh - 기본정보 확인
# 도커 정보 확인 : Client 와 Server , Storage Driver(overlay2), Cgroup Version(2), Default Runtime(runc) $ sudo docker info # Client: # Context: default # Debug Mode: false # # Server: # Containers: 0 # ... # Server Version: 20.10.25+dfsg1 # Storage Driver: overlay2 # ... # Cgroup Driver: systemd # Cgroup Version: 2 # ... # containerd version: 1.6.24~ds1-2 # runc version: 1.1.12+ds1-5 # ... $ sudo docker version # => Client: # Version: 20.10.25+dfsg1 # API version: 1.41 # Go version: go1.22.3 # Git commit: b82b9f3 # Built: Tue May 7 10:33:18 2024 # OS/Arch: linux/amd64 # Context: default # Experimental: true # # Server: # Engine: # Version: 20.10.25+dfsg1 # API version: 1.41 (minimum version 1.12) # Go version: go1.22.3 # Git commit: 5df983c # Built: Tue May 7 10:33:18 2024 # OS/Arch: linux/amd64 # Experimental: false # ... # 도커 서비스 상태 확인 $ sudo systemctl status docker -l --no-pager # 모든 서비스의 상태 표시 $ systemctl list-units --type=service # 도커 루트 디렉터리 확인 : Docker Root Dir(/var/lib/docker) $ sudo tree -L 3 /var/lib/docker # => /var/lib/docker # |-- buildkit # | ... # |-- containers # |-- image # | `-- overlay2 # | |-- distribution # | |-- imagedb # | |-- layerdb # | `-- repositories.json # |-- network # | `-- files # | `-- local-kv.db # |-- overlay2 # | ... # `-- volumes # |-- backingFsBlockDev # `-- metadata.db # # 24 directories, 8 files - 네트워크 정보 확인
# 프로세스 확인 - 셸변수 $ ps -ef # 프로세스 목록 보기 $ pstree -p # 프로세스 트리로 보기 $ df -hT # 디스크 사용량 확인 # 네트워크 정보 확인. 도커에서 사용하는 docker0 네트워크가 추가되어있고 현재 DOWN 상태입니다. # 컨테이너가 있으면 UP 상태로 변경됩니다. $ ip -br -c addr # => <span style="color:teal;">lo </span>UNKNOWN <span style="color:purple;">127.0.0.1</span>/8 <span style="color:blue;">::1</span>/128 # <span style="color:teal;">eth0 </span><span style="color:green;">UP </span><span style="color:purple;">10.10.10.109</span>/24 <span style="color:purple;">10.10.10.51</span>/24 <span style="color:blue;">fe80::a70d:8639:be6:671e</span>/64 # <span style="color:teal;">docker0 </span><span style="color:red;">DOWN </span><span style="color:purple;">172.17.0.1</span>/16 <span style="color:blue;">fe80::42:57ff:fe56:997c</span>/64 $ ip -c addr $ ip -c link $ ip -br -c link $ ip -c route # 이더넷 브릿지 정보 확인 $ brctl show # => bridge name bridge id STP enabled interfaces # docker0 8000.02425756997c no # iptables 정책 확인 # FORWARD 정책이 DROP으로 설정되어 있고, # docker0에서 docker0 혹은 외부로 전달되는 패킷은 허용되어 있습니다. $ sudo iptables -t filter -S # => -P INPUT ACCEPT # <span style="color: red;">-P FORWARD DROP</span> # -P OUTPUT ACCEPT # -N DOCKER # -N DOCKER-ISOLATION-STAGE-1 # -N DOCKER-ISOLATION-STAGE-2 # -N DOCKER-USER # -A FORWARD -j DOCKER-USER # -A FORWARD -j DOCKER-ISOLATION-STAGE-1 # -A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT # -A FORWARD -o docker0 -j DOCKER # <span style="color: red;">-A FORWARD -i docker0 ! -o docker0 -j ACCEPT</span> # <span style="color: red;">-A FORWARD -i docker0 -o docker0 -j ACCEPT</span> # -A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2 # -A DOCKER-ISOLATION-STAGE-1 -j RETURN # -A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP # -A DOCKER-ISOLATION-STAGE-2 -j RETURN # -A DOCKER-USER -j RETURN # NAT POSTROUTING에 172.17.0.0/16에서 외부로 전달시 MASQUERADE (SNAT) 정책이 설정되어 있습니다. $ sudo iptables -t nat -S # => -P PREROUTING ACCEPT # -P INPUT ACCEPT # -P OUTPUT ACCEPT # -P POSTROUTING ACCEPT # -N DOCKER # -A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER # -A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER # <span style="color: red;">-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE</span> # -A DOCKER -i docker0 -j RETURN
도커를 비 root 유저로 관리하기
도커는 기본적으로 root로 관리할 수 있습니다. root가 아닌 유저로 docker 명령을 실행하면 다음과 같은 에러가 발생합니다.
$ whoami
# => kali
$ docker info
# => ...
# Server:
# ERROR: permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/info": dial unix /var/run/docker.sock: connect: permission denied
하지만, 다음의 방법 처럼 현재 사용자를 docker 그룹에 추가하면, root가 아닌 일반 유저로도 관리할 수 있습니다.
$ whoami
# => kali
$ echo $USER
# => kali
# 도커 그룹 추가
$ sudo usermod -aG docker $USER
# 그룹 확인
$ groups
# => adm ... kaboxer
# 로그아웃
exit
# ssh 재접속 후 확인
$ groups
# => adm ... kaboxer docker
$ docker info
# => Client:
# Context: default
# Debug Mode: false
#
# Server:
# Containers: 0
# ...
# Cgroup Version: 2
# ...
# Default Runtime: runc
# Init Binary: docker-init
# containerd version: 1.6.24~ds1-2
# runc version: 1.1.12+ds1-5
# ...
# 컨테이너 확인
$ docker run --rm hello-world
# => Hello from Docker!
# This message shows that your installation appears to be working correctly.
# ...
# 실행중인 도커 컨테이너 확인
$ docker ps
# 전체 도커 컨테이너 확인
$ docker ps -a
# 이미지 목록 확인
$ docker images
# => REPOSITORY TAG IMAGE ID CREATED SIZE
# hello-world latest d2c94e258dcb 16 months ago 13.3kB
# 도커 컨테이너 삭제
$ docker ps -aq
$ docker rm -f $(docker ps -aq)
$ docker ps -a
컨테이너가 host의 docker socket file 공유로 도커 실행
-
도커 컨테이너를 GUI로 관리할 수 있는 툴인 portainer처럼 도커 컨테이너가 호스트의 도커 소켓 파일을 공유하여 도커를 관리하는데 사용 할 수 있습니다.
# 도커 컨테이너 실행 $ docker run -d -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock portainer/portainer-ce $ docker ps # => CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES # 1495728fd014 portainer/portainer-ce "/portainer" 2 minutes ago Up 2 minutes 8000/tcp, 9443/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp wizardly_ride-v옵션으로 호스트의 도커 소켓 파일을 컨테이너의 도커 소켓 파일로 공유하면 아래와 같이 도커 컨테이너에서 호스트의 도커를 관리할 수 있습니다.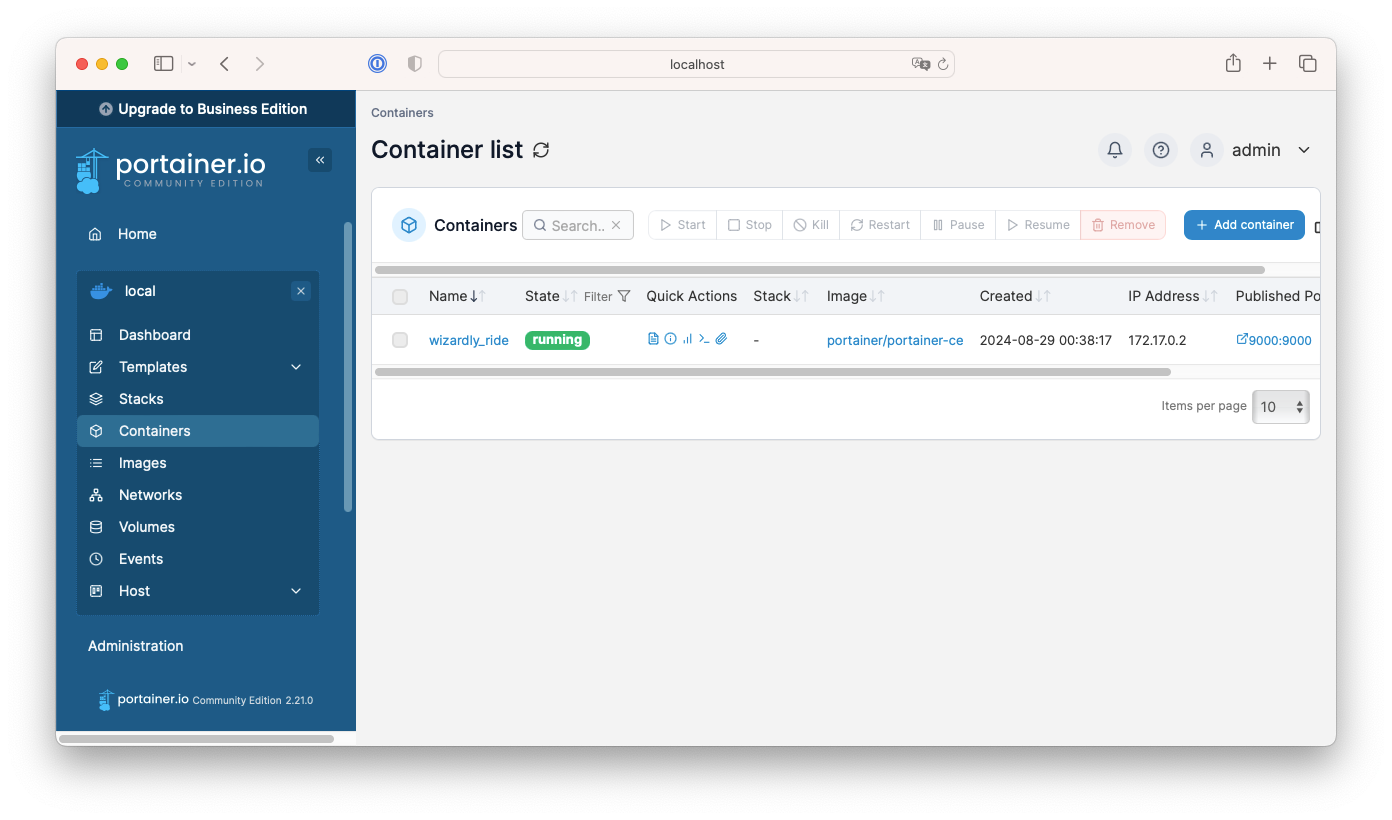
-
또한 Jenkins 같은 CI/CD 툴을 사용할때도 도커 소켓 파일을 공유하여 도커 기반 워커를 사용할 수도 있습니다.
CPU 아키텍쳐
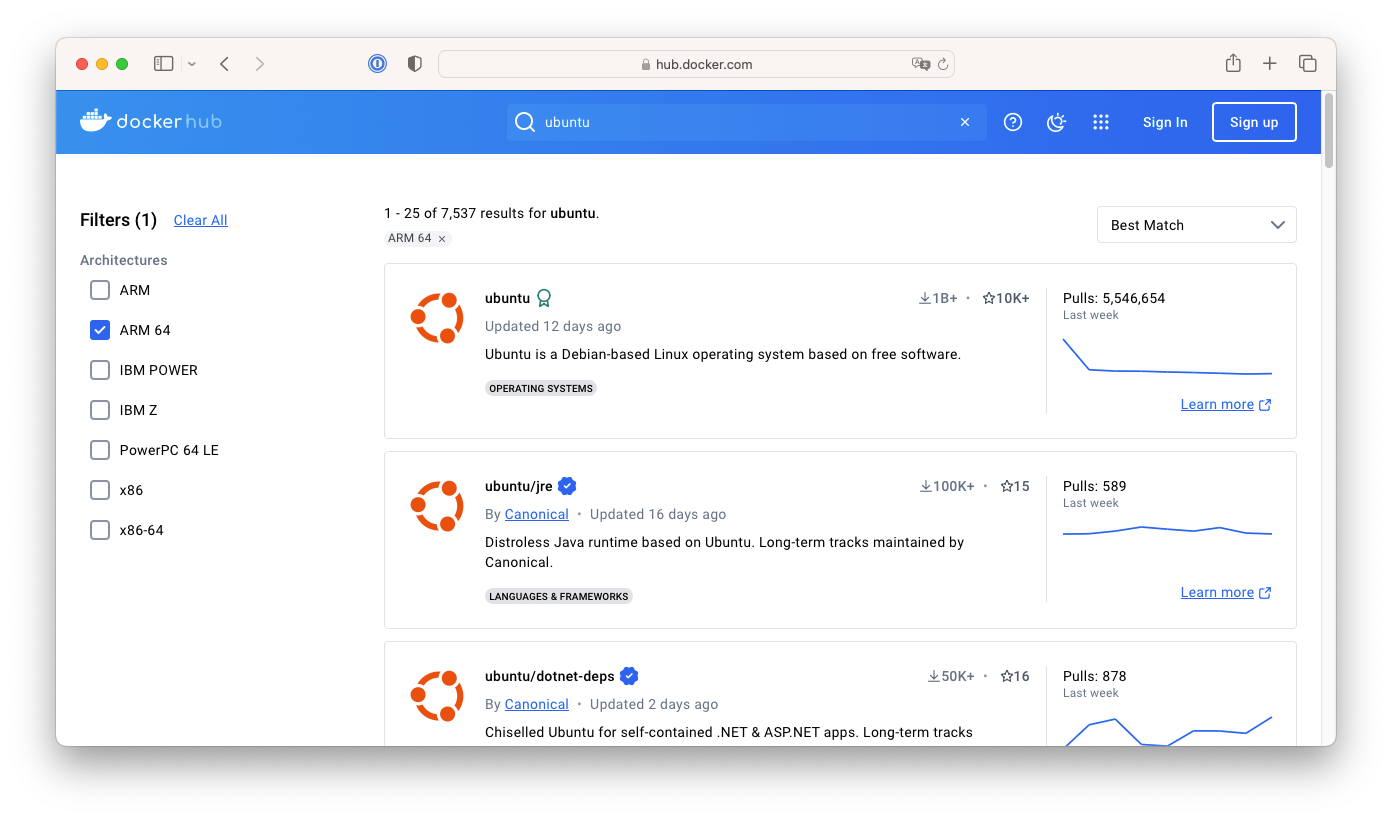
- 도커 허브에 등록된 이미지들은 CPU 아키텍쳐별로 이미지를 제공하는데, 호스트의 CPU 아키텍쳐와 다른 이미지는 동작할 수 없습니다.
- 아래와 같이 docker hub에서는 지원 CPU 아키텍쳐별로 필터링하는 기능을 제공하니, 특정 아키텍쳐의 이미지가 필요한 경우 사용할 수 있습니다.
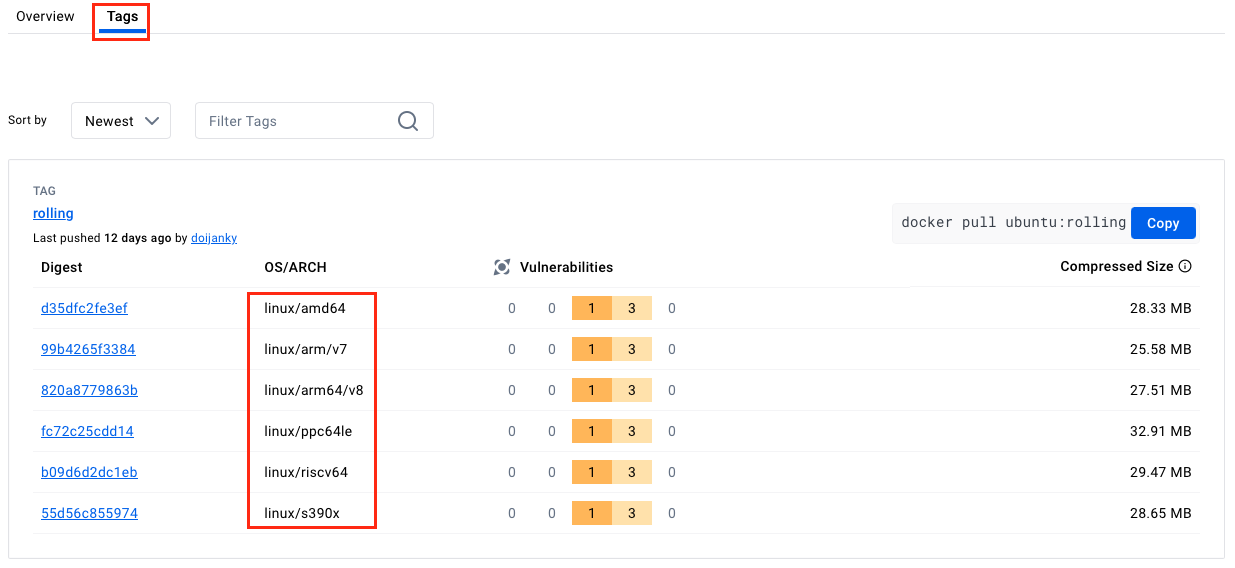
- 또한 도커이미지 페이지의 Tags 탭에서 태그의 지원하는 아키텍쳐를 확인할 수 있습니다.
- 현재 리눅스의 CPU 아키텍쳐를 확인 해보겠습니다.
$ lscpu # => Architecture: x86_64 # CPU op-mode(s): 32-bit, 64-bit # ...사용중인 CPU 아키텍쳐는 x86_64 입니다.
- 현재 CPU 아키텍쳐와는 다른 아키텍쳐의 이미지를 설치해서 실패하는것을 확인해 보겠습니다.
# arm64 실행 실패 $ docker run --rm -it arm64v8/ubuntu bash # => WARNING: The requested image's platform (linux/arm64/v8) does not match the detected host platform (linux/amd64) and no specific platform was requested # exec /usr/bin/bash: exec format error # riscv64 실행 실패 $ docker run --rm -it riscv64/ubuntu bash # => WARNING: The requested image's platform (linux/riscv64) does not match the detected host platform (linux/amd64) and no specific platform was requested # exec /usr/bin/bash: exec format error
컨테이너 격리
- docker는 리눅스의 프로세스 격리 기술을 활용하는데, 프로세스 격리 기술은 chroot에서 부터 cgroup, namespace 등을 거쳐 발전하고 있습니다.
- 주요 격리 기술들을 실습해보며 이해해보겠습니다.
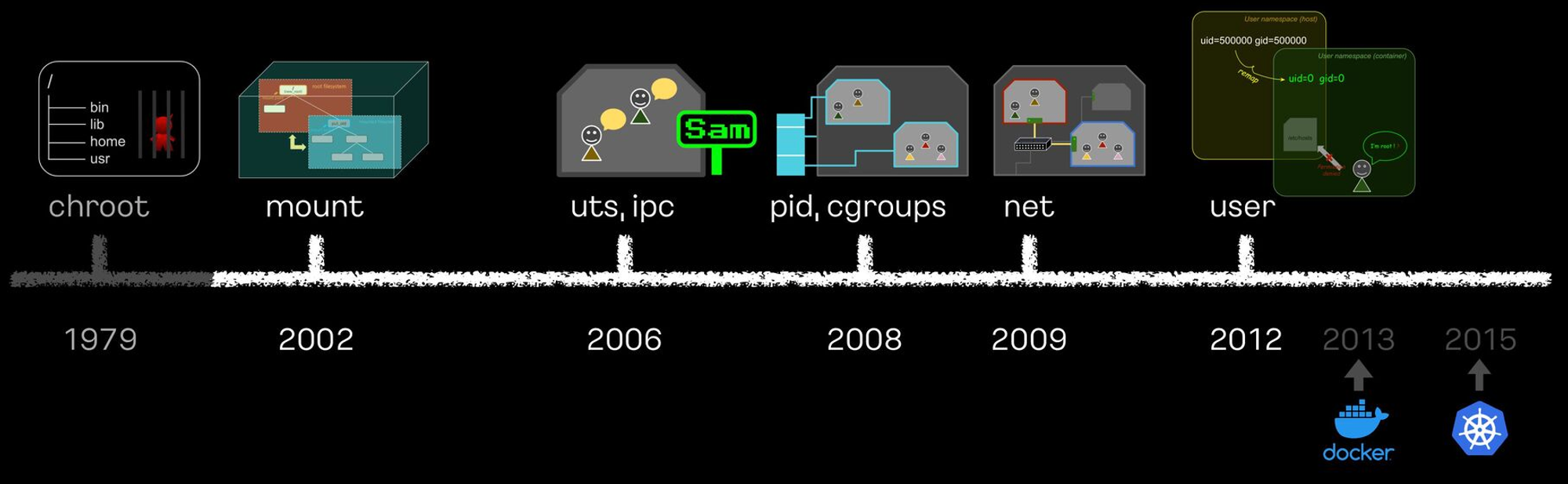 https://speakerdeck.com/kakao/ige-dwaeyo-dokeo-eobsi-keonteineo-mandeulgi?slide=200
https://speakerdeck.com/kakao/ige-dwaeyo-dokeo-eobsi-keonteineo-mandeulgi?slide=200
chroot
- chroot는 리눅스의 프로세스 격리 기술 중 하나로, 프로세스가 접근할 수 있는 파일 시스템의 루트 디렉터리를 변경하는 기술입니다.
- 1979년에 처음 등장했으며, 한계가 뚜렷하지만 다양한 목적으로 현재도 현역으로 사용되고 있습니다.
# 관리자 전환
$ sudo -i
$ whoami
# => root
$ cd /tmp
$ mkdir myroot
# chroot 실행 (chroot [새 루트] [명령])
$ chroot myroot /bin/bash
# => chroot: failed to run command ‘/bin/bash’: No such file or directory
- /tmp/myroot 로 chroot하려니 bash가 없어서 실행이 되지 않습니다. bash를 복사해 넣어보겠습니다.
# bash를 실행하는데 필요한 라이브러리를 확인하겠습니다.
$ ldd /bin/bash
# => linux-vdso.so.1 (0x00007fffecfa8000)
# libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007fbfe6a4f000)
# libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fbfe686a000)
# /lib64/ld-linux-x86-64.so.2 (0x00007fbfe6be0000)
$ mkdir -p myroot/bin
$ cp /bin/bash myroot/bin
$ mkdir -p myroot/{lib64,lib/x86_64-linux-gnu}
$ cp /lib/x86_64-linux-gnu/libtinfo.so.6 myroot/lib/x86_64-linux-gnu
$ cp /lib/x86_64-linux-gnu/libc.so.6 myroot/lib/x86_64-linux-gnu
$ cp /lib64/ld-linux-x86-64.so.2 myroot/lib64
$ tree myroot
# => myroot
# |-- bin
# | `-- bash
# |-- lib
# | `-- x86_64-linux-gnu
# | |-- libc.so.6
# | `-- libtinfo.so.6
# `-- lib64
# `-- ld-linux-x86-64.so.2
#
# 5 directories, 4 files
$ chroot myroot /bin/bash
# => bash-5.2#
# bash와 bash에 필요한 라이브러리를 넣어주니 chroot로 실행할 수 있게 되었습니다.
# ls를 실행해보겠습니다.
$ ls
# => bash: ls: command not found
# ls가 없어서 실행이 되지 않습니다. ls를 넣기위해 chroot에서 나오겠습니다.
$ exit
# ls 위치 확인
$ whereis ls
# => ls: /usr/bin/ls /usr/share/man/man1/ls.1.gz
$ ldd /usr/bin/ls
# ldd로 확인된 라이브러리를 포함해 ls를 myroot에 넣어보겠습니다.
$ cp /usr/bin/ls myroot/bin
$ cp /lib/x86_64-linux-gnu/libselinux.so.1 myroot/lib/x86_64-linux-gnu
$ cp /lib/x86_64-linux-gnu/libpcre2-8.so.0 myroot/lib/x86_64-linux-gnu
$ chroot myroot /bin/bash
# ls시 /tmp/myroot에 있는 파일들을 확인할 수 있습니다.
$ ls
# => bin lib lib64
# 현재 디렉터리 확인시 / 로 되어있습니다. 이 처럼 chroot로 인해 루트 디렉터리가 변경되었습니다.
$ pwd
# => /
$ cd ../../..
$ ls
# => bin lib lib64
# chroot를 종료 합니다.
$ exit
- 이 작업을 반복하면 거의 모든 프로그램을 chroot로 실행할 수 있습니다. 하지만 /proc, /dev 등의 가상 디렉터리는 다음의 방법으로 넣어주어야 합니다.
# 다음 동작은 chroot 밖의 호스트에서 실행해야 합니다.
# mount 할 디렉터리 만들어주기
$ mkdir -p myroot/{proc,dev}
# /proc, /dev 마운트
$ mount -t proc none myroot/proc
$ mount -o bind /dev myroot/dev
# /proc 확인을 위해 ps도 chroot 환경에 넣어보겠습니다.
$ cp /usr/bin/ps myroot/bin
$ cp /lib/x86_64-linux-gnu/{libproc2.so.0,libc.so.6,libsystemd.so.0,libcap.so.2,libgcrypt.so.20,liblz4.so.1,liblzma.so.5,libzstd.so.1,libgpg-error.so.0} myroot/lib/x86_64-linux-gnu/
$ cp /lib64/ld-linux-x86-64.so.2 myroot/lib64/
$ chroot myroot /bin/bash
$ ls /proc
$ ps
# => PID TTY TIME CMD
# 729517 ? 00:00:00 sudo
# 741301 ? 00:00:00 bash
# 741310 ? 00:00:00 ps
# chroot 종료
$ exit
# 마운트 해제
$ mount -t proc
# => proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
# none on /tmp/myroot/proc type proc (rw,relatime)
$ umount myroot/proc
$ umount myroot/dev
$ mount -t proc
# => proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
- 도커 컨테이너 이미지를 추출하여 chroot로 실행해보겠습니다.
$ mkdir nginx-root
# nginx 컨테이너 이미지에서 파일들을 추출하여 nginx-root에 넣어줍니다.
$ docker export $(docker create nginx) | tar -C nginx-root -xvf -
$ docker images
$ tree -L 2 nginx-root
# chroot로 nginx-root를 루트 디렉터리로 변경합니다.
$ chroot nginx-root /bin/bash
# nginx를 실행해봅니다.
$ nginx -g 'daemon off;'
# [터미널2] 터미널을 하나더 열고 nginx 동작 여부를 확인합니다.
$ ps -f -C nginx
$ curl localhost
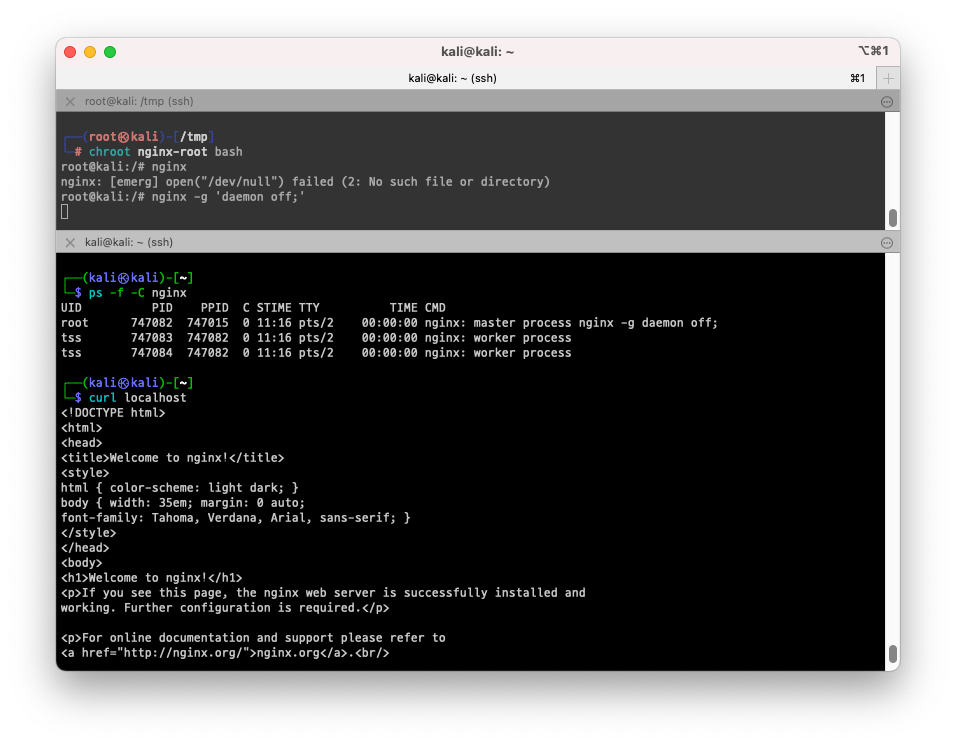
# 생성된 docker 컨테이너를 확인합니다. docker create nginx로 인해 컨테이너가 생겨져있습니다.
$ docker ps -a
# => CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 0b506af00006 nginx "/docker-entrypoint.…" About a minute ago Created gifted_rosalind
# 사용하지 않는 도커이미지를 지워줍니다.
$ docker rm 0b5
- 아쉽게도 chroot는 탈옥이 가능하다고 합니다. 다음 코드를 컴파일하여 탈옥을 시도해보겠습니다.
#include <sys/stat.h>
#include <unistd.h>
int main(void)
{
mkdir(".out", 0755);
chroot(".out");
chdir("../../../../../");
chroot(".");
return execl("/bin/sh", "-i", NULL);
}
# 컴파일
$ gcc -o myroot/escape_chroot escape_chroot.c
$ file myroot/escape_chroot
# => myroot/escape_chroot: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=5a40e26463d1015f870c7f1b9db9be159727c250, for GNU/Linux 3.2.0, not stripped
# chroot 실행
$ chroot myroot /bin/bash
$ ls
$ cd ../../
$ cd ../../
$ ls
# 일반적인 방법으로는 myroot에서 벗어날 수 없었습니다.
# escape_chroot 실행해서 탈옥해보겠습니다.
$ ./escape_chroot
$ ls /
# 탈옥이 잘 되었습니다.
# 종료
$ exit
$ exit
마운트 네임스페이스 + pivot_root
-
pivot_root는 루트 파일 시스템을 변경하는 시스템 콜로, 루트 디렉터리를 변경하는 chroot와 달리 루트 파일 시스템을 별도의 디렉터리로 이동시킬 수 있습니다. - 아래의 그림에서 처럼 /tmp/new_root가 있고 /tmp/new_root/put_old 디렉터리가 있는 경우,
pivot_root /tmp/new_root /tmp_new_root/put_old를 하면 /tmp/new_root가 루트 디렉터리로 변경되고, 원래의 루트 /는 /tmp/new_root/put_old로 이동됩니다.
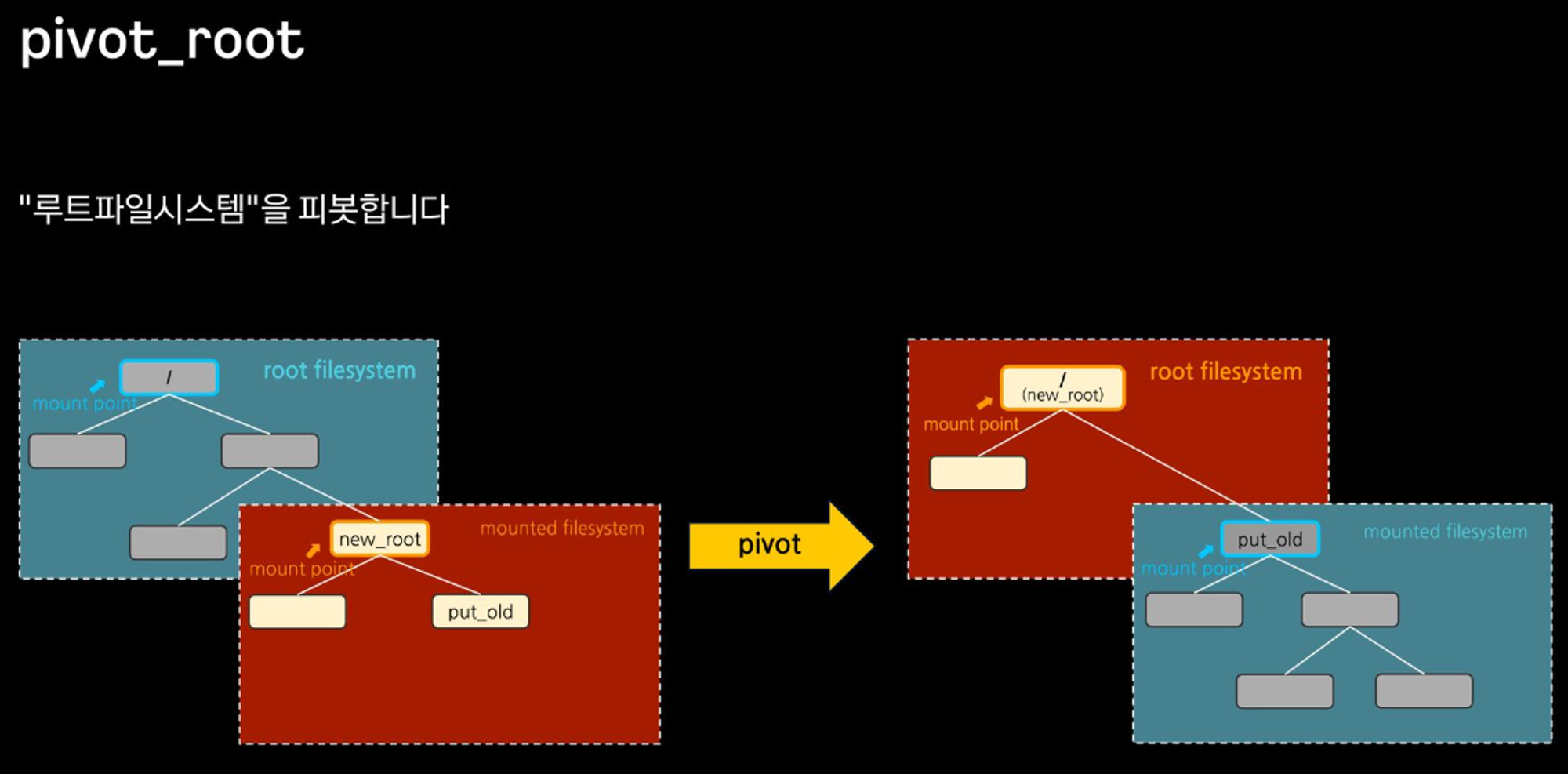 https://speakerdeck.com/kakao/ige-dwaeyo-dokeo-eobsi-keonteineo-mandeulgi?slide=80
https://speakerdeck.com/kakao/ige-dwaeyo-dokeo-eobsi-keonteineo-mandeulgi?slide=80
-
pivot_root를 사용하려면unshare명령을 통해 마운트 네임스페이스를 만들어야 합니다. 마운트 네임스페이스는 리눅스 커널에서 제공하는 기능으로, 프로세스가 마운트 정보를 독립적으로 가질 수 있게 해줍니다. - 또한 다음과 같은 제약사항이 적용 됩니다.
- new_root와 put_old가 디렉터리여야 한다.
- new_root와 put_old가 현재 루트와 같은 마운트 상에 있어선 안 된다.
- put_old가 new_root와 같거나 그 아래에 있어야 한다. 즉, put_old가 가리키는 경로명 앞에 “/..”를 0개 이상 붙여서 new_root와 같은 디렉터리가 나와야 한다.
- new_root가 마운트 지점의 경로여야 하되, “/”일 수 없다. 마운트 지점이 아닌 경우에는 그 경로를 스스로에게 바인드 마운트 해서 마운트 지점으로 바꿀 수 있다.
- new_root의 부모 마운트 및 현재 작업 디렉터리의 부모 마운트의 전파 유형이 MS_SHARED여선 안 된다. 마찬가지로 put_old가 기존 마운트 지점인 경우 그 전파 유형이 MS_SHARED여선 안 된다. 이 제약은 pivot_root()로 인해 다른 마운트 네임스페이스로 어떤 변화도 전파되지 않게 한다.
- 현재 루트 디렉터리가 마운트 지점이어야 한다.
- 실습을 통해 마운트 네임스페이스와 pivot_root를 알아보겠습니다.
실습
- 먼저 pivot_root로 root 디렉터리로 만들 /tmp/new_root를 만들어보겠습니다.
- 위의 제약사항 중 new_root와 put_old가 현재 루트와 같은 마운트 상에 있어서는 안 되기 때문에 new_root를 tmpfs 로 마운트 하겠습니다.
$ mkdir /tmp/new_root
# 마운트
$ mount -t tmpfs tmpfs /tmp/new_root
# 기존 루트를 이동시킬 /tmp/new_root/put_old 디렉터리를 만들기
$ mkdir /tmp/new_root/put_old
# /bin, /lib, /lib64 등 chroot 실습때 사용했던 /tmp/myroot를 /tmp/new_root 로 복사해서 재사용합니다.
$ cp -rv /tmp/myroot/* /tmp/new_root
$ mount -t proc proc /tmp/new_root/proc
# unshare 해서 마운트 네임스페이스를 만들어줍니다.
$ unshare --mount /bin/bash
$ cd /tmp/new_root
# pivot_root를 실행
$ pivot_root . put_old
# 새로운 루트로 이동되었습니다.
# 새 루트 확인
$ ls /
# => bin dev escape_chroot lib lib64 proc put_old
# 기존 루트 확인
$ ls /put_old
# => bin dev home lib32 lost+found mnt proc run srv sys usr vmlinuz
# boot etc initrd.img lib lib64 media opt root sbin swapfile tmp var
- 새로운 루트로 이동되었지만, 기존 루트에 있는 파일들을 삭제하거나 이동하지 않았기 때문에 /put_old로 기존 루트에 있는 파일들을 확인할 수 있습니다.
- 하지만 umount를 사용하면 /put_old와 기존 루트의 연결을 끊어서 기존 루트를 숨길 수 있습니다.
$ umount -l /put_old
$ ls /put_old
# => (공백)
- escape_root를 통해 탈옥을 시도해보겠습니다.
# 탈옥 시도
$ /escape_chroot
$ ls /
# => bin dev escape_chroot lib lib64 proc put_old
$ cd ../../..
$ /escape_chroot
$ ls /
# => bin dev escape_chroot lib lib64 proc put_old
- chroot와 달리 pivot_root는 탈옥이 불가능하고 훨씬 안전한것 같습니다.
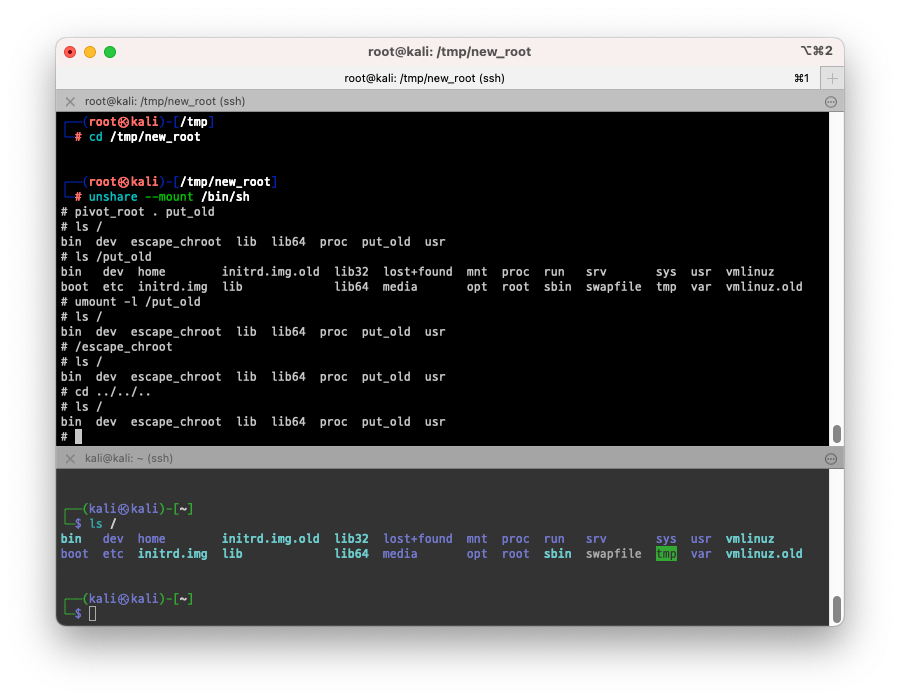
네임스페이스 (namespace)
- 여기에서의 네임스페이스는 쿠버네티스 등의 네임스페이스와는 다른, 리눅스 커널에서 제공하는 프로세스 격리 기술로, 프로세스가 각종 자원을 격리하여 사용할 수 있게 해줍니다.
- 주요 네임스페이스의 유형은 아래와 같습니다.
- Mount Namespace (2002년 도입)
- pivot_root 예제에서 처럼 마운트 정보를 격리합니다.
- 즉, 서로 다른 네임스페이스가 독립적으로 파일 시스템을 마운트 할 수 있습니다.
- UTS Namespace (2006년 도입)
- 호스트 이름과 NIS 도메인 이름을 격리합니다. 각 네임스페이스는 자체 호스트 이름과 NIS 도메인 이름을 가질 수 있고, 이를 통해 호스트 이름을 변경하더라도 다른 네임스페이스에 영향을 주지 않습니다.
- IPC Namespace (2006년 도입)
- POSIX 메시지 큐, 세마포어, 공유 메모리 같은 IPC 리소스를 격리합니다.
- 이를 통해 서로 다른 네임스페이스는 독립적으로 System V IPC 객체와 POSIX 메시지 큐를 사용할 수 있습니다.
- PID Namespace (2008년 도입)
- 프로세스 ID를 격리합니다. 각 네임스페이스는 자체 PID를 가질 수 있으며 자체적인 PID 1을 가질 수 있습니다.
- 프로세스 ID가 1인것은 시스템 시작시에 최초로 실행된 것이며 이를 init 프로세스라고 합니다. 이 프로세스가 종료되면 시스템이 종료되거나 다시 부팅됩니다. 도커 컨테이너 실행시 실행되는 프로그램이 PID가 1이고, 해당 프로그램이 종료되며 컨테이너도 종료되는게 이때문입니다.
- Network Namespace (2009년 도입)
- 네트워크 인터페이스, IP 주소, 라우팅 테이블, 방화벽 규칙 등 네트워크 리소스를 격리합니다.
- 각 네임스페이스는 자체 네트워크 인터페이스, IP 주소, 라우팅 테이블, 방화벽 규칙을 가질 수 있습니다.
- USER Namespace (2012년 도입)
- 사용자 ID와 그룹 ID를 격리합니다. 각 네임스페이스는 자체 사용자 ID와 그룹 ID를 가질 수 있습니다.
- 이를 통해 root 권한을 가진 사용자도 일반 사용자로 격리하여 사용할 수 있고, 일반 사용자도 root 인것 처럼 보이게 할 수 있습니다.
- 실행 중인 도커컨테이너에서는 ps로 확인시 root로 실행 중인데, 호스트에서 ps로 확인시 일반 사용자로 실행 중인것 처럼 보이는것도 이것 때문입니다.
- CGROUP Namespace (2016년 도입)
- CGROUP은 프로세스의 그룹으로 CPU, 메모리, 디스크 I/O, 네트워크 등의 자원을 제한하거나 할당할 수 있습니다.
- CGROUP Namespace는 CPU, 메모리 등의 자원을 제한하거나 할당할 수 있는 CGROUP을 격리하는 기능입니다.
- Mount Namespace (2002년 도입)
cgroup 를 이용한 자원관리
- cgroups는 control groups의 줄일말로 리눅스 커널에서 제공하는 자원 제한 및 할당 기능으로, CPU, 메모리, 디스크 I/O, 네트워크 등의 자원을 제한하거나 할당할 수 있습니다.
- 프로세스는 실행중인 프로그램의 인스턴스를 의미하며, OS에서는 프로세스를 관리하기 위해 프로세스 ID(PID)를 사용합니다.
- cgroups는 프로세스를 그룹으로 묶어서 자원을 제한하거나 할당할 수 있습니다.
- cgroups는 /sys/fs/cgroup 디렉터리에 마운트되어 있으며, cgroup v1과 cgroup v2가 있습니다.
# cgroup 버전 확인
$ mount | grep cgroup
# => cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
- 현재 테스트 시스템에는 cgroup v2가 사용되고 있는것을 확인할 수 있습니다.
- cgroup v2는 v1에 비해 자원 계층구조의 가시성이 향상 되었고, memoryQoS 라는 기능이 추가되어 컨테이너에서 OOM(Out Of Memory)이 발생가능성을 줄였습니다. 최신 리눅스 배포판은 보통 cgroup v2를 사용하고 있어서 cgroup v2로 실습을 진행하겠습니다.
- cgroup의 계층 구조는 /sys/fs/cgroup 에서 확인할 수 있습니다.
- /proc는 보았지만 /sys는 눈에 익지 않습니다. 리눅스 커널 3.x 버전에서 생긴것으로 USER SPACE 쪽은 /proc에 KERNEL SPACE 쪽 정보는 /sys에 들어간다고 합니다.
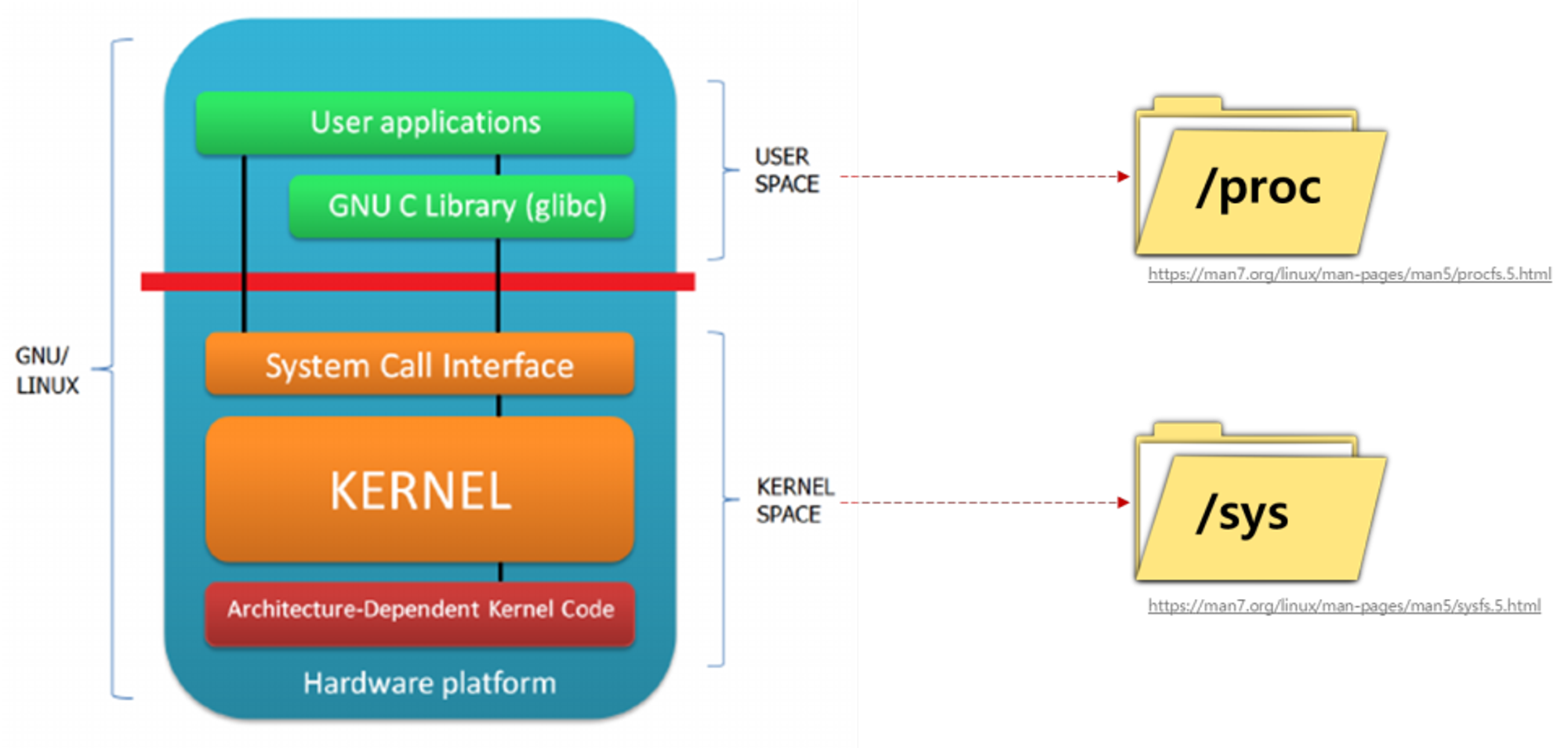 출처 : https://blog.naver.com/yu3papa/223562337709
출처 : https://blog.naver.com/yu3papa/223562337709
- 실습을 통해 cgroup의 정보를 확인해 보겠습니다.
$ mount -t cgroup
$ mount -t cgroup2
# => cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
$ findmnt -t cgroup2
# => TARGET SOURCE FSTYPE OPTIONS
# /sys/fs/cgroup cgroup2 cgroup2 rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot
# cgroupv1 만 지원 시, cgroup2 출력되지 않음
$ grep cgroup /proc/filesystems
# => nodev cgroup
# nodev cgroup2
$ stat -fc %T /sys/fs/cgroup/
# => cgroup2fs
# 터미널2
$ sleep 100000
# 터미널1
# /proc 에 cgroup 정보 확인
$ cat /proc/cgroups
$ cat /proc/$(pgrep sleep)/cgroup
# => 0::/user.slice/user-1000.slice/session-713.scope
$ tree /proc/$(pgrep sleep) -L 2
# => ...
# |-- <span style="font-weight:bold;color:blue;">ns</span>
# | |-- <span style="font-weight:bold;color:teal;">cgroup</span> -> cgroup:[4026531835]
# | |-- <span style="font-weight:bold;color:teal;">ipc</span> -> ipc:[4026531839]
# | |-- <span style="font-weight:bold;color:teal;">mnt</span> -> mnt:[4026531841]
# | |-- <span style="font-weight:bold;color:teal;">net</span> -> net:[4026531840]
# ...
# cgroup 목록 확인
$ ls /sys/fs/cgroup
$ cat /sys/fs/cgroup/cgroup.controllers
# => cpuset cpu io memory hugetlb pids rdma misc
$ tree /sys/fs/cgroup/ -L 1
$ tree /sys/fs/cgroup/ -L 2
$ tree /sys/fs/cgroup/user.slice -L 1
$ tree /sys/fs/cgroup/user.slice/user-1000.slice -L 1
- 이번에는 cgroup을 이용하여 자원을 제한하는 실습을 진행해보겠습니다.
# 터미널 2개를 열어서 root 로 실습 하겠습니다.
$ sudo -i
$ whoami
# => root
# 툴 설치
$ apt install -y cgroup-tools stress htop
# 터미널2
# CPU 사용률 확인을 위해 htop을 실행합니다.
$ htop
# 터미널1에서 실습 진행
# 1개 CPU 코어에 부하 발생을 위해 stress를 실행합니다.
$ stress --cpu 1
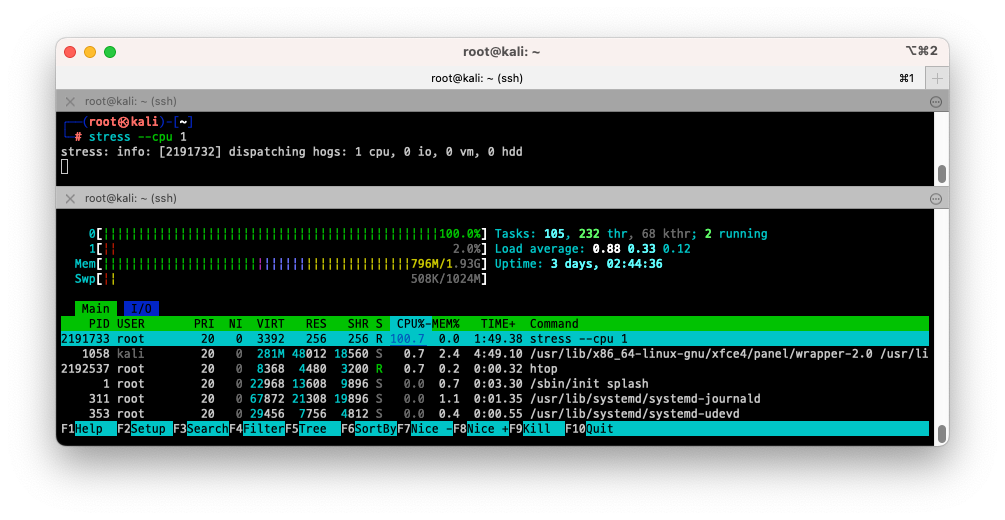
- CPU 0만 100% 사용중인것을 확인할 수 있습니다.
$ cd /sys/fs/cgroup
$ mkdir test_cgroup_parent && cd test_cgroup_parent
$ tree
# 제어가능한 항목 확인
$ cat cgroup.controllers
# => cpuset cpu io memory hugetlb pids rdma misc
# cpu를 subtree이 추가하여 컨트롤 할 수 있도록 설정 : +/-(추가/삭제)
$ cat cgroup.subtree_control
$ echo "+cpu" >> /sys/fs/cgroup/test_cgroup_parent/cgroup.subtree_control
# cpu.max 제한 설정 : 첫 번쨰 값은 허용된 시간(마이크로초) 두 번째 값은 총 기간 길이 > 1/10 실행 설정
$ echo 100000 1000000 > /sys/fs/cgroup/test_cgroup_parent/cpu.max
# test용 자식 디렉토리를 생성하고, pid를 추가하여 제한을 걸어
$ mkdir test_cgroup_child && cd test_cgroup_child
$ echo $$ > /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child/cgroup.procs
$ cat /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child/cgroup.procs
# => 1947587
# 2194781
$ cat /proc/$$/cgroup
# => 0::/test_cgroup_parent/test_cgroup_child
# 부하 발생 확인 : 터미널2에 htop 확인
$ stress --cpu 1
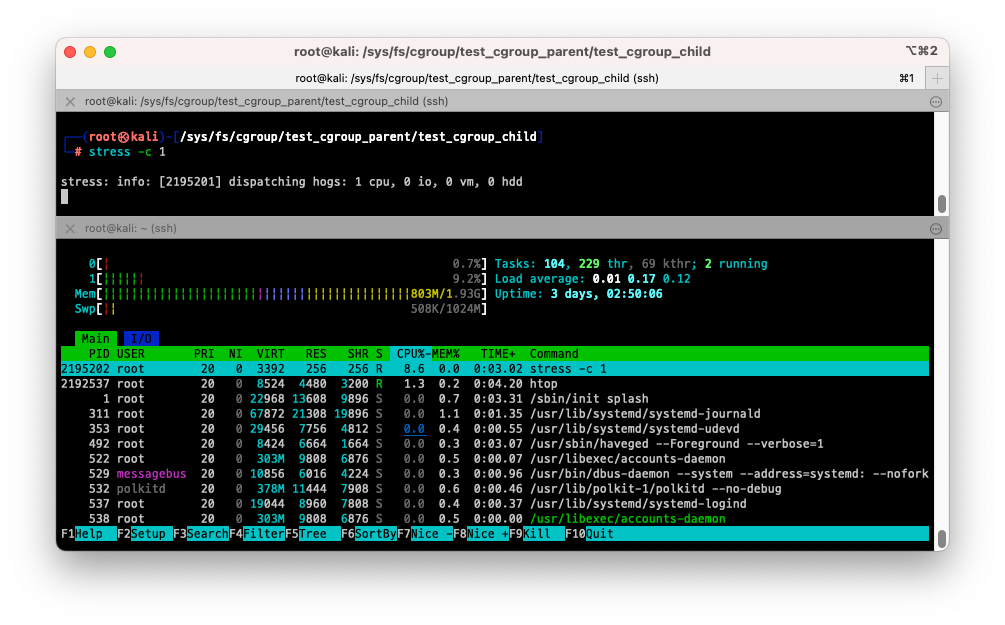
- cpu.max 제한 설정에서 설정한 대로 (100000/1000000 => 10%) CPU 사용량이 10%로 제한된것을 확인할 수 있습니다.
- 값 수정을 해서 100%로 변경해보겠습니다.
# 값 수정
$ echo 1000000 1000000 > /sys/fs/cgroup/test_cgroup_parent/cpu.max
# 부하 발생 확인 : 터미널2에 htop 확인
$ stress --cpu 1
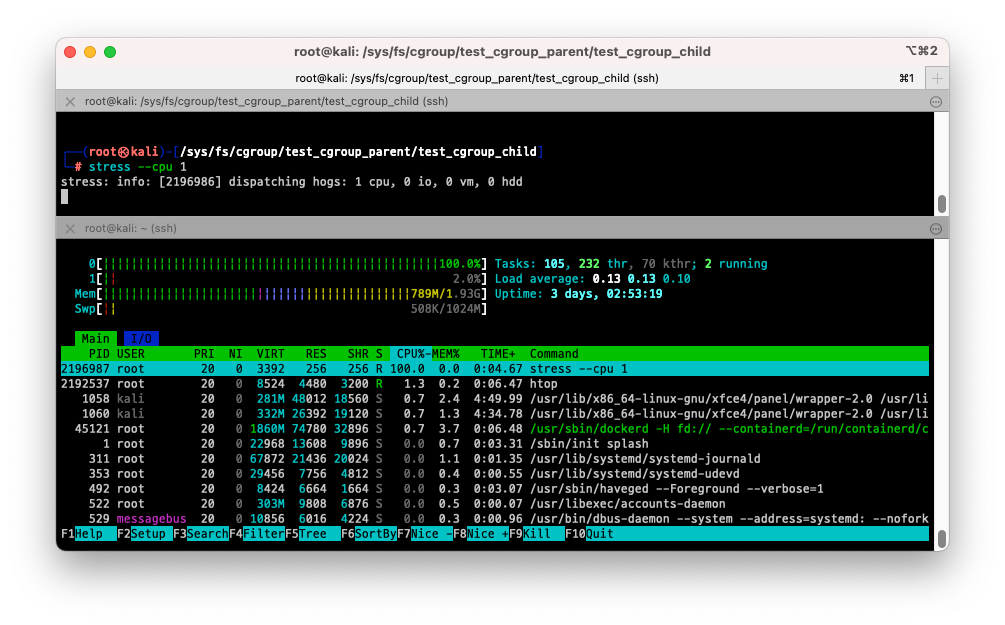
- 테스트에 사용한 cgroup 을 삭제하고 실습을 마무리하겠습니다.
$ exit
$ sudo -i
$ rmdir /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child
$ rmdir /sys/fs/cgroup/test_cgroup_parent
- 이상과 같이 cgroup을 사용하여 cpu 자원을 제한하는것을 실습해 보았습니다.

컨테이너 네트워크 & Iptables
- 도커는 호스트와 컨테이너간, 컨테이너 간의 네트워크를 앞에서 살펴본 네트워크 네임스페이스를 통해 격리합니다.
- 또한 iptables를 통해 네트워크 패킷을 제어하고, 컨테이너 간의 통신을 제어합니다.
- 실습을 통해 네트워크 네임스페이스를 통한 격리와 iptables의 사용법에 대해 알아보겠습니다.
Red <=> Blue 네트워크 네임스페이스 간 통신
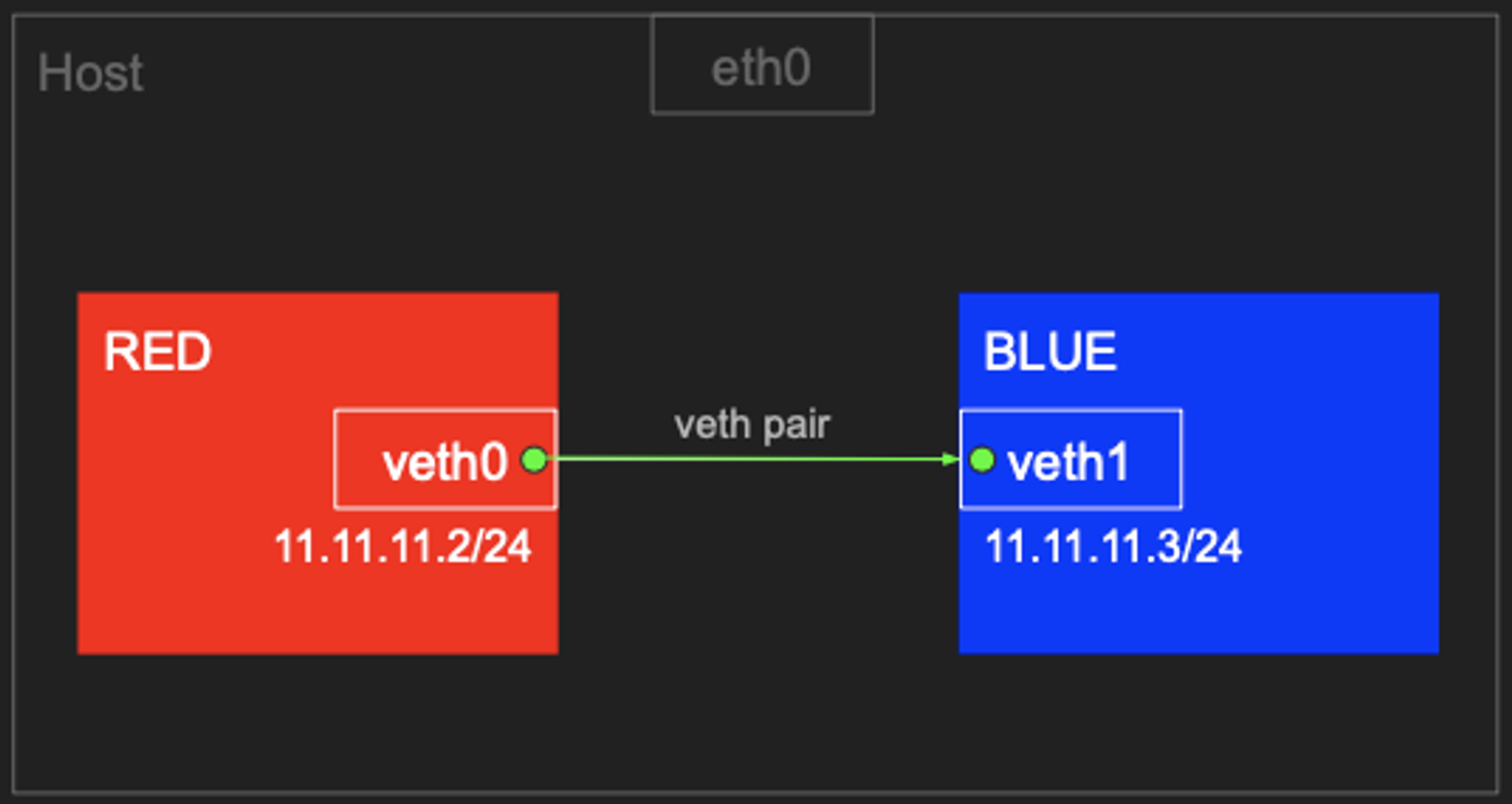
- 먼저 터미널 3개를 열고 모두 관리자로 로그인 하겠습니다.
$ sudo -i
$ whoami
# => root
- veth (Virtual Ethernet)를 사용하여 Red와 Blue 네트워크 네임스페이스를 만듭니다.
$ ip link add veth0 type veth peer name veth1
# veth 생성 확인 (상태 DOWN)
$ ip link
# => 22: <span style="color:teal;">veth1@veth0: </span><BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>mode DEFAULT group default qlen 1000
# link/ether <span style="color:olive;">9e:74:34:5c:70:ef</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span>
# 23: <span style="color:teal;">veth0@veth1: </span><BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>mode DEFAULT group default qlen 1000
# link/ether <span style="color:olive;">72:c0:05:36:cd:1b</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span>
$ ip addr | grep veth
# => 22: <span style="color:teal;">veth1@veth0: </span><BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>group default qlen 1000
# link/ether <span style="color:olive;">9e:74:34:5c:70:ef</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span>
# 23: <span style="color:teal;">veth0@veth1: </span><BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>group default qlen 1000
# link/ether <span style="color:olive;">72:c0:05:36:cd:1b</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span>
# 네트워크 네임스페이스 생성
$ ip netns add RED
$ ip netns add BLUE
# 네트워크 네임스페이스 확인
$ ip netns
# => RED
# BLUE
# veth0와 veth1을 각각 RED와 BLUE 네트워크 네임스페이스로 이동시킵니다.
$ ip link set veth0 netns RED
$ ip link set veth1 netns BLUE
# 네트워크 네임스페이스 확인. id 라는것이 추가되었습니다.
$ ip netns list
# => RED (id: 0)
# BLUE (id: 1)
# ip 링크를 확인하면 veth0와 veth1이 각각 RED와 BLUE 네트워크 네임스페이스로 이동되어 기본 명령에서는 보이지 않습니다.
$ ip link | grep "veth."
# => (공백)
# ip netns exec [네임스페이스명] [명령] 으로 네트워크 네임스페이스에서 명령을 실행할 수 있습니다.
$ ip netns exec RED ip link
# => 1: <span style="color:teal;">lo: </span><LOOPBACK> mtu 65536 qdisc noop state <span style="color:red;">DOWN </span>mode DEFAULT group default qlen 1000
# link/loopback <span style="color:olive;">00:00:00:00:00:00</span> brd <span style="color:olive;">00:00:00:00:00:00</span>
# 23: <span style="color:teal;">veth0@if22: </span><BROADCAST,MULTICAST> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>mode DEFAULT group default qlen 1000
# link/ether <span style="color:olive;">72:c0:05:36:cd:1b</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netns BLUE
$ ip netns exec BLUE ip link
# => 1: <span style="color:teal;">lo: </span><LOOPBACK> mtu 65536 qdisc noop state <span style="color:red;">DOWN </span>mode DEFAULT group default qlen 1000
# link/loopback <span style="color:olive;">00:00:00:00:00:00</span> brd <span style="color:olive;">00:00:00:00:00:00</span>
# 22: <span style="color:teal;">veth1@if23: </span><BROADCAST,MULTICAST> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>mode DEFAULT group default qlen 1000
# link/ether <span style="color:olive;">9e:74:34:5c:70:ef</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netns RED
# veth0과 veth1을 활성화 (UP) 시키겠습니다.
$ ip netns exec RED ip link set veth0 up
# veth0의 IP 확인
$ ip netns exec RED ip addr
# => ...
# 23: <span style="color:teal;">veth0@if22: </span><BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state <span style="color:green;">UP </span>group default qlen 1000
# link/ether <span style="color:olive;">72:c0:05:36:cd:1b</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netns BLUE
# inet6 <span style="color:blue;">fe80::70c0:5ff:fe36:cd1b</span>/64 scope link proto kernel_ll
# valid_lft forever preferred_lft forever
$ ip netns exec BLUE ip link set veth1 up
$ ip netns exec BLUE ip addr
# => ...
# 22: <span style="color:teal;">veth1@if23: </span><BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state <span style="color:green;">UP </span>group default qlen 1000
# link/ether <span style="color:olive;">9e:74:34:5c:70:ef</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netns RED
# inet6 <span style="color:blue;">fe80::9c74:34ff:fe5c:70ef</span>/64 scope link proto kernel_ll
# valid_lft forever preferred_lft forever
# UP 상태로 되었으나 IP가 없습니다. IP를 할당해보겠습니다.
$ ip netns exec RED ip addr add 11.11.11.2/24 dev veth0
$ ip netns exec BLUE ip addr add 11.11.11.3/24 dev veth1
# IP 를 확인해보겠습니다.
$ ip netns exec RED ip addr
# => ...
# 23: <span style="color:teal;">veth0@if22: </span><BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state <span style="color:green;">UP </span>group default qlen 1000
# link/ether <span style="color:olive;">72:c0:05:36:cd:1b</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netns BLUE
# inet <span style="color:purple;">11.11.11.2</span>/24 scope global veth0
# valid_lft forever preferred_lft forever
# inet6 <span style="color:blue;">fe80::70c0:5ff:fe36:cd1b</span>/64 scope link proto kernel_ll
# valid_lft forever preferred_lft forever
$ ip netns exec BLUE ip addr
# => ...
# 22: <span style="color:teal;">veth1@if23: </span><BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state <span style="color:green;">UP </span>group default qlen 1000
# link/ether <span style="color:olive;">9e:74:34:5c:70:ef</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netns RED
# inet <span style="color:purple;">11.11.11.3</span>/24 scope global veth1
# valid_lft forever preferred_lft forever
# inet6 <span style="color:blue;">fe80::9c74:34ff:fe5c:70ef</span>/64 scope link proto kernel_ll
# valid_lft forever preferred_lft forever
- 이제 Red와 Blue 네트워크 네임스페이스 간의 통신을 테스트 해보겠습니다.
-
nsenter명령을 사용하여 네트워크에 attach 하고,tcpdump와ping을 사용하여 통신을 확인합니다. -
tcpdump는 네트워크 패킷을 캡처하는 명령어로, 패킷을 캡처하여 확인할 수 있고,ping은 네트워크 상태를 확인하는 명령어입니다.
$ tree /var/run/netns
# => <span style="font-weight:bold;color:blue;">/var/run/netns</span>
# |-- BLUE
# `-- RED
#
# 1 directory, 2 files
# 터미널 1 (RED 11.11.11.2)
# 네트워크 네임스페이스에 attach.
# 이때 --net 옵션을 사용해 앞에서 확인한 /var/run/netns/RED를 사용해 네트워크 네임스페이스에 attach 합니다.
$ nsenter --net=/var/run/netns/RED
# 이웃하는 IP/ARP 정보 확인
$ ip neigh
# => (공백)
# 라우팅 정보, iptables 정보
$ ip route
# => <span style="color:purple;">11.11.11.0/24 </span>dev <span style="color:teal;">veth0 </span>proto kernel scope link src <span style="color:purple;">11.11.11.2 </span>
$ iptables -t filter -S
$ iptables -t nat -S
# 터미널 2 (호스트)
# 네트워크 네임스페이스 상태 확인
$ lsns -t net
# => NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
# ...
# 4026532444 net 1 1940569 root 0 /run/netns/RED -zsh
# 4026532527 net 0 root /run/netns/BLUE
# 네트워크 정보 확인
$ ip addr
$ ip neigh
$ ip route
$ iptables -t filter -S
$ iptables -t nat -S
# 터미널 3 (BLUE 11.11.11.3)
$ nsenter --net=/var/run/netns/BLUE
$ ip neigh
$ ip route
$ iptables -t filter -S
$ iptables -t nat -S
# ping 통신 확인
# 터미널3 (BLUE)
$ tcpdump -i veth1
$ ip -c neigh
$ exit
# 터미널1 (RED)
$ ping 11.11.11.3 -c 1
$ ip -c neigh
$ exit
# 네임스페이스 삭제
$ ip netns del RED
$ ip netns del BLUE
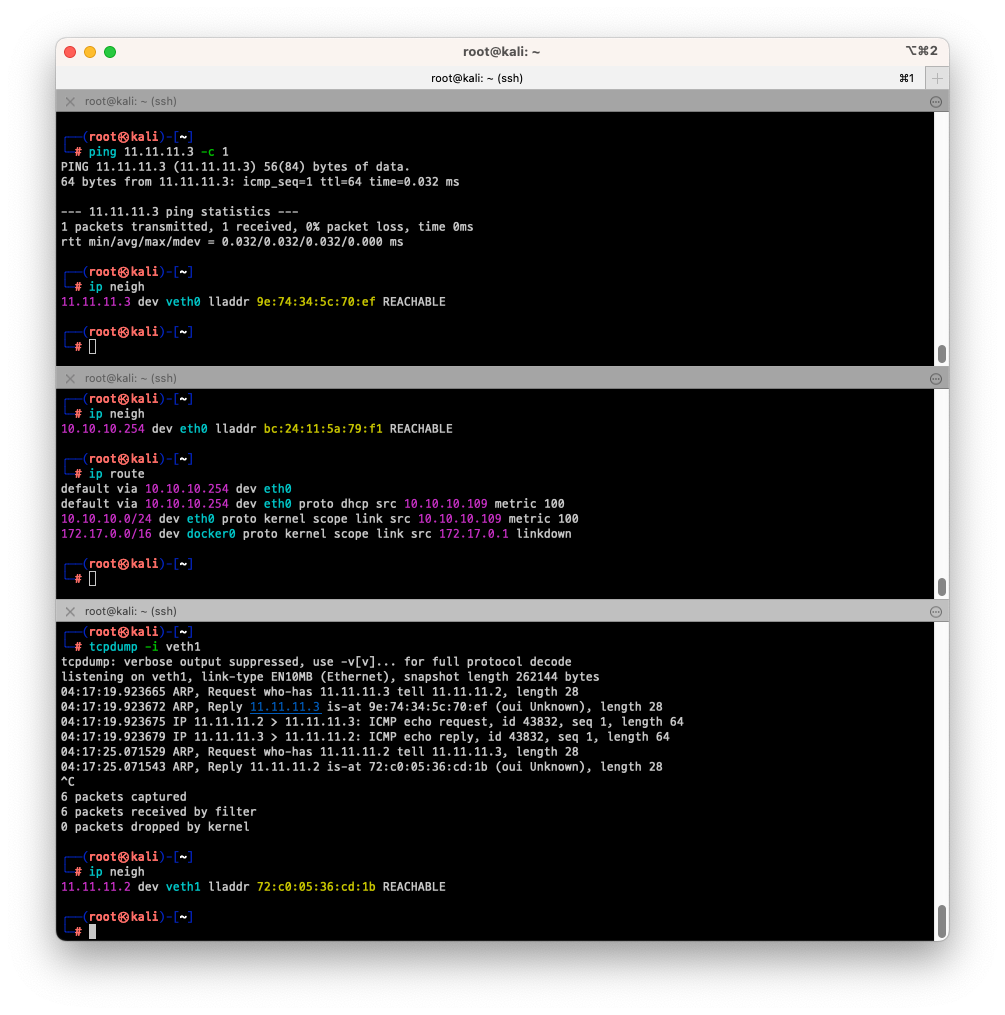
- 위의 캡쳐와 같이 통신이 되어서 tcpdump에 ARP, ICMP 패킷이 잡히는것을 확인할 수 있습니다.
- 또한
ip neigh명령을 확인했을때 ARP 테이블에 상대방의 IP와 MAC 주소가 등록되어 있는것을 확인할 수 있습니다.
Red <- Bridge (br0) -> Blue 네트워크 네임스페이스 간 통신
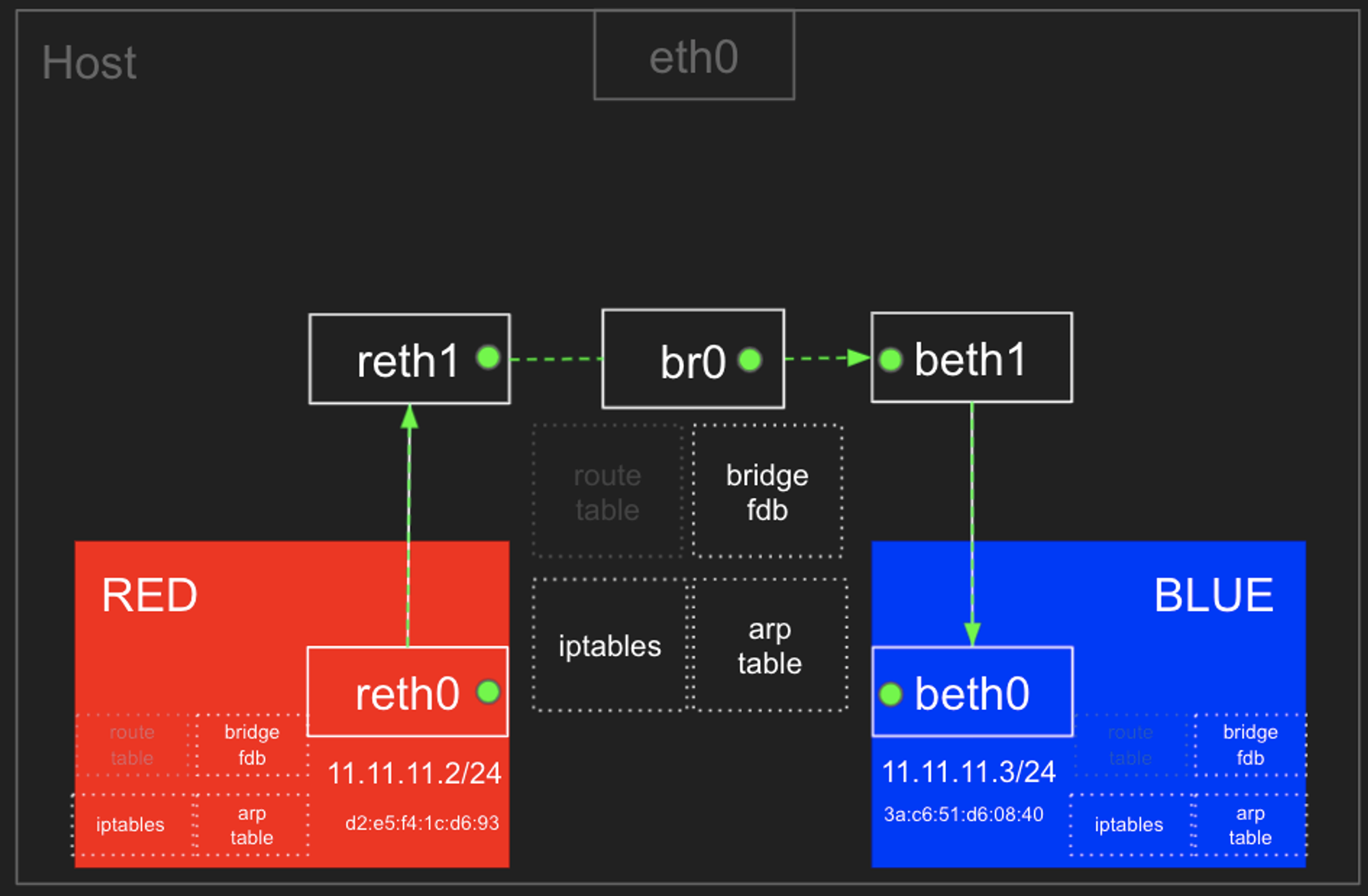
- 이전 실습에서는 Red와 Blue를 연결하여 peer 네트워크로 구성하였는데, 이번에는 각각 독립적인 네트워크로 구성하여 Bridge를 사용하여 Red와 Blue 네트워크 네임스페이스 간의 통신을 확인해보겠습니다.
- 왜 Bridge를 두는가 하면, peer 네트워크를 구성할 경우 구성원들 간의 통신을 위해서는 모든 노드가 서로서로 연결되어야 하기 때문입니다.
- Bridge를 두면 각 노드는 Bridge와만 연결되어 있으면 통신이 가능하므로 효율적입니다.
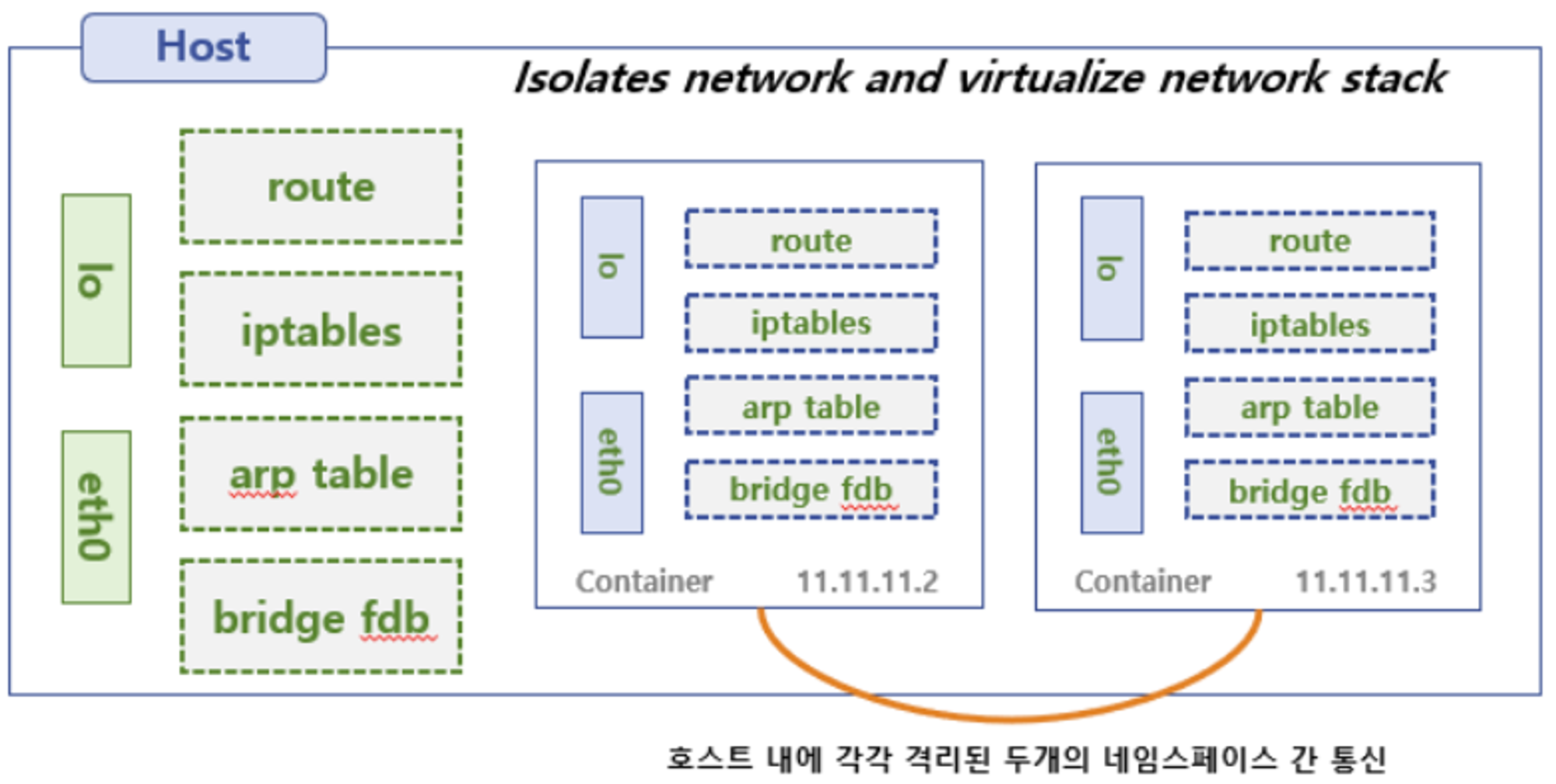
- 실습을 통해 아래의 그림과 같이 격리된 네트워크 네임스페이스를 만들고 브릿지를 통해 통신해보겠습니다.
# 터미널 3개를 root 로 엽니다.
$ sudo -i
$ whoami
# => root
# 네트워크 네임스페이스 및 veth 생성
$ ip netns add RED
$ ip link add reth0 type veth peer name reth1
$ ip link set reth0 netns RED
$ ip netns add BLUE
$ ip link add beth0 type veth peer name beth1
$ ip link set beth0 netns BLUE
# 확인
$ ip netns list
$ ip link
# => ...
# 26: <span style="color:teal;">reth1@if27: </span><BROADCAST,MULTICAST> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>mode DEFAULT group default qlen 1000
# link/ether <span style="color:olive;">9a:1f:bf:6f:fe:64</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netns RED
# 28: <span style="color:teal;">beth1@if29: </span><BROADCAST,MULTICAST> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>mode DEFAULT group default qlen 1000
# link/ether <span style="color:olive;">7e:31:cf:5f:00:8f</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netns BLUE
$ ip netns exec RED ip addr
# => ...
# 27: <span style="color:teal;">reth0@if26: </span><BROADCAST,MULTICAST> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>group default qlen 1000
# link/ether <span style="color:olive;">ea:7f:a0:1f:00:3d</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netnsid 0
$ ip netns exec BLUE ip addr
# => ...
# 29: <span style="color:teal;">beth0@if28: </span><BROADCAST,MULTICAST> mtu 1500 qdisc noop state <span style="color:red;">DOWN </span>group default qlen 1000
# link/ether <span style="color:olive;">66:23:89:a6:f7:70</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span> link-netnsid 0
# 브릿지 정보 확인
$ brctl show
# => bridge name bridge id STP enabled interfaces
# docker0 8000.02425756997c no
# br0 브릿지 생성
$ ip link add br0 type bridge
# br0 브릿지 정보 확인
$ brctl show br0
# => bridge name bridge id STP enabled interfaces
# br0 8000.000000000000 no
$ brctl showmacs br0
$ brctl showstp br0
# reth1과 beth1을 br0 브릿지에 연결
$ ip link set reth1 master br0
$ ip link set beth1 master br0
$ brctl show br0
# => bridge name bridge id STP enabled interfaces
# br0 8000.7e31cf5f008f no beth1
# reth1
$ brctl showmacs br0
# => port no mac addr is local? ageing timer
# 2 7e:31:cf:5f:00:8f yes 0.00
# 2 7e:31:cf:5f:00:8f yes 0.00
# 1 9a:1f:bf:6f:fe:64 yes 0.00
# 1 9a:1f:bf:6f:fe:64 yes 0.00
$ ip -br link
# => ...
# <span style="color:teal;">reth1@if27 </span><span style="color:red;">DOWN </span><span style="color:olive;">9a:1f:bf:6f:fe:64 </span><BROADCAST,MULTICAST>
# <span style="color:teal;">beth1@if29 </span><span style="color:red;">DOWN </span><span style="color:olive;">7e:31:cf:5f:00:8f </span><BROADCAST,MULTICAST>
# <span style="color:teal;">br0 </span><span style="color:red;">DOWN </span><span style="color:olive;">7e:31:cf:5f:00:8f </span><BROADCAST,MULTICAST>
# reth0과 beth0에 IP 설정 및 활성화(UP) 시키고, reth1, beth1, br0를 활성화(UP) 합니다.
$ ip netns exec RED ip addr add 11.11.11.2/24 dev reth0
$ ip netns exec BLUE ip addr add 11.11.11.3/24 dev beth0
$ ip netns exec RED ip link set reth0 up
$ ip link set reth1 up
$ ip netns exec BLUE ip link set beth0 up
$ ip link set beth1 up
$ ip link set br0 up
$ ip -br addr
# => ...
# <span style="color:teal;">reth1@if27 </span><span style="color:green;">UP </span><span style="color:blue;">fe80::981f:bfff:fe6f:fe64</span>/64
# <span style="color:teal;">beth1@if29 </span><span style="color:green;">UP </span><span style="color:blue;">fe80::7c31:cfff:fe5f:8f</span>/64
# <span style="color:teal;">br0 </span><span style="color:green;">UP </span><span style="color:blue;">fe80::7c31:cfff:fe5f:8f</span>/64
$ ip netns exec RED ip -br addr
# => ...
# <span style="color:teal;">reth0@if26 </span><span style="color:green;">UP </span><span style="color:purple;">11.11.11.2</span>/24 <span style="color:blue;">fe80::e87f:a0ff:fe1f:3d</span>/64
$ ip netns exec BLUE ip -br addr
# => ...
# <span style="color:teal;">beth0@if28 </span><span style="color:green;">UP </span><span style="color:purple;">11.11.11.3</span>/24 <span style="color:blue;">fe80::6423:89ff:fea6:f770</span>/64
# 터미널1 (RED 11.11.11.2)
$ nsenter --net=/var/run/netns/RED
$ ip -c a;echo; ip -c route;echo; ip -c neigh
# 현재 네트워크 네임스페이스 확인
$ ip netns identify $$
# => RED
# 터미널2 (호스트)
$ brctl showmacs br0
$ bridge fdb show
$ bridge fdb show dev br0
$ iptables -t filter -S
$ iptables -t filter -L -n -v
# 터미널3 (BLUE 11.11.11.3)
$ nsenter --net=/var/run/netns/BLUE
$ ip -c a;echo; ip -c route;echo; ip -c neigh
# 현재 네트워크 네임스페이스 확인
$ ip netns identify $$
# => BLUE
# 터미널2 (호스트)
# ping 통신 전 사전 설정
## iptables 정보 확인
$ iptables -t filter -S | grep '\-P'
# => -P INPUT ACCEPT
# -P FORWARD DROP
# -P OUTPUT ACCEPT
$ iptables -nvL -t filter
# 호스트에서 패킷 라우팅 설정 확인 - 0(off), 1(on)
$ cat /proc/sys/net/ipv4/ip_forward
# => 1
# 위의 결과가 0인 경우 아래의 명령을 실행
# echo 1 > /proc/sys/net/ipv4/ip_forward
# ping 통신 확인
# 터미널2 (호스트)
$ tcpdump -l -i br0
# => tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
# listening on br0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
# (터미널1에서 ping 실행시)
# 08:40:00.413198 IP 11.11.11.2 > 11.11.11.3: ICMP echo request, id 41028, seq 1, length 64
# 08:40:05.455528 ARP, Request who-has 11.11.11.3 tell 11.11.11.2, length 28
# 08:40:05.455556 ARP, Reply 11.11.11.3 is-at 66:23:89:a6:f7:70 (oui Unknown), length 28
$ watch -d 'iptables -v --numeric --table filter --list FORWARD'
$ watch -d 'iptables -v --numeric --table filter --list FORWARD;echo;iptables -v --numeric --table filter --list DOCKER-USER;echo;iptables -v --numeric --table filter --list DOCKER-ISOLATION-STAGE-1'
# 터미널3 (BLUE 11.11.11.3)
$ tcpdump -l -i beth0
# 터미널1 (RED 11.11.11.2)
$ ping 11.11.11.3 -c 1
# => 실패
위의 캡쳐와 같이 브릿지에서는 패킷이 잡히지만, 브릿지를 통해 Blue로 패킷이 전달되지 않는것을 확인할 수 있습니다.
그렇다면 왜 패킷이 전달되지 않을까요? 그것은 iptables -t filter -S | grep '\-P' 명령을 통해 확인했을때 FORWARD 체인이 DROP으로 설정되어 있기 때문입니다.
패킷이 브릿지를 통해 전달되려면 FORWARD 체인을 통해야 하는데 DROP이면 패킷이 전달되지 않습니다.
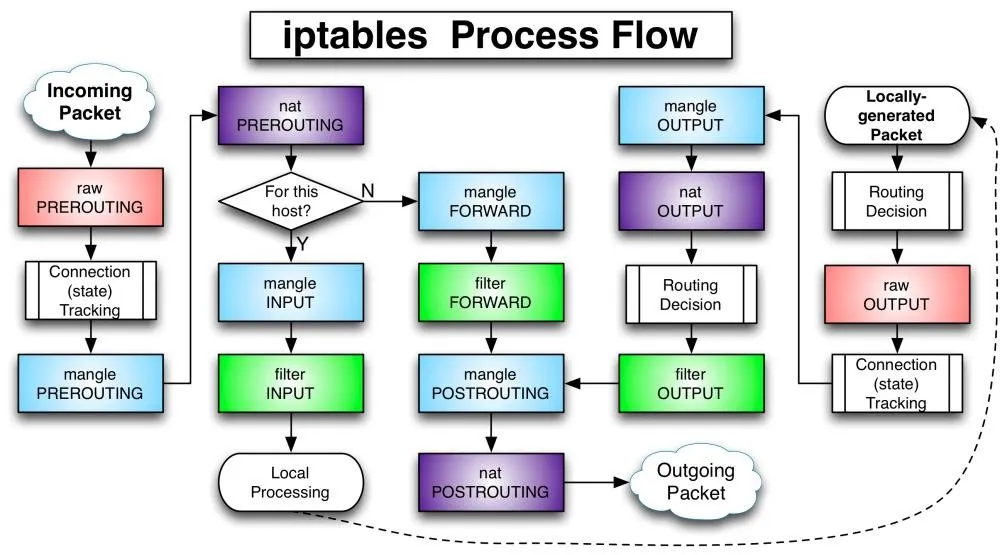 Iptables 처리 흐름도 (https://natnat1.medium.com/iptables-b9ce0602253f)
Iptables 처리 흐름도 (https://natnat1.medium.com/iptables-b9ce0602253f)
- 위의 그림과 같이 iptables는 패킷이 들어오면 PREROUTING 체인을 통해 패킷을 처리하고, FORWARD 체인을 통해 패킷을 전달합니다.
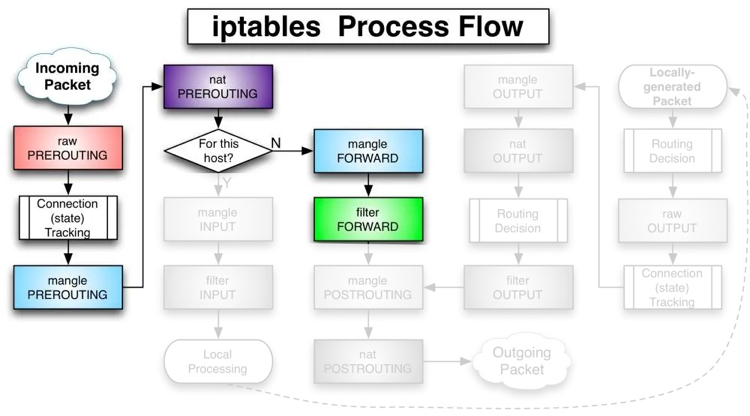
- br0 입장에서 살펴보면 위와 같습니다. 그렇다면 11.11.11.2 <=> 11.11.11.3으로 FORWARD를 허용하면 되는데 방법을 살펴보면 아래와 같습니다.
- 출발지 11.11.11.2와 11.11.11.3 허용
- 도착지 11.11.11.0/24 대역 출발지 허용
- FORWARD 기본 정책을 ACCEPT로 변경
- 등등 기타 어떤 방법으로든 11.11.11.2와 11.11.11.3이 FORWARD 체인을 통해 패킷이 전달되도록 설정하면 됩니다.
- 실습을 통해 iptables를 통해 패킷이 전달되도록 설정해보겠습니다.
- 방법1. 11.11.11.2와 11.11.11.3 허용하기
# 터미널2 (호스트) # 출발지 11.11.11.2 허용하기 $ iptables -t filter -A FORWARD -s 11.11.11.2/32 -j ACCEPT $ iptables -t filter -A FORWARD -s 11.11.11.3/32 -j ACCEPT $ tcpdump -l -i br0 # 터미널3 (BLUE 11.11.11.3) $ tcpdump -l -i beth0 # => tcpdump: verbose output suppressed, use -v[v]... for full protocol decode # listening on beth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes # 10:39:20.225225 IP 11.11.11.2 > 11.11.11.3: ICMP echo request, id 33335, seq 1, length 64 # 10:39:20.225233 IP 11.11.11.3 > 11.11.11.2: ICMP echo reply, id 33335, seq 1, length 64 # 터미널1 (RED 11.11.11.2) $ ping 11.11.11.3 # => PING 11.11.11.3 (11.11.11.3) 56(84) bytes of data. # 64 bytes from 11.11.11.3: icmp_seq=1 ttl=64 time=0.055 ms # # --- 11.11.11.3 ping statistics --- # 1 packets transmitted, 1 received, 0% packet loss, time 0ms # rtt min/avg/max/mdev = 0.055/0.055/0.055/0.000 ms # 터미널2 (호스트) # 허용 룰 제거 $ iptables -t filter -D FORWARD -s 11.11.11.2/32 -j ACCEPT $ iptables -t filter -D FORWARD -s 11.11.11.3/32 -j ACCEPT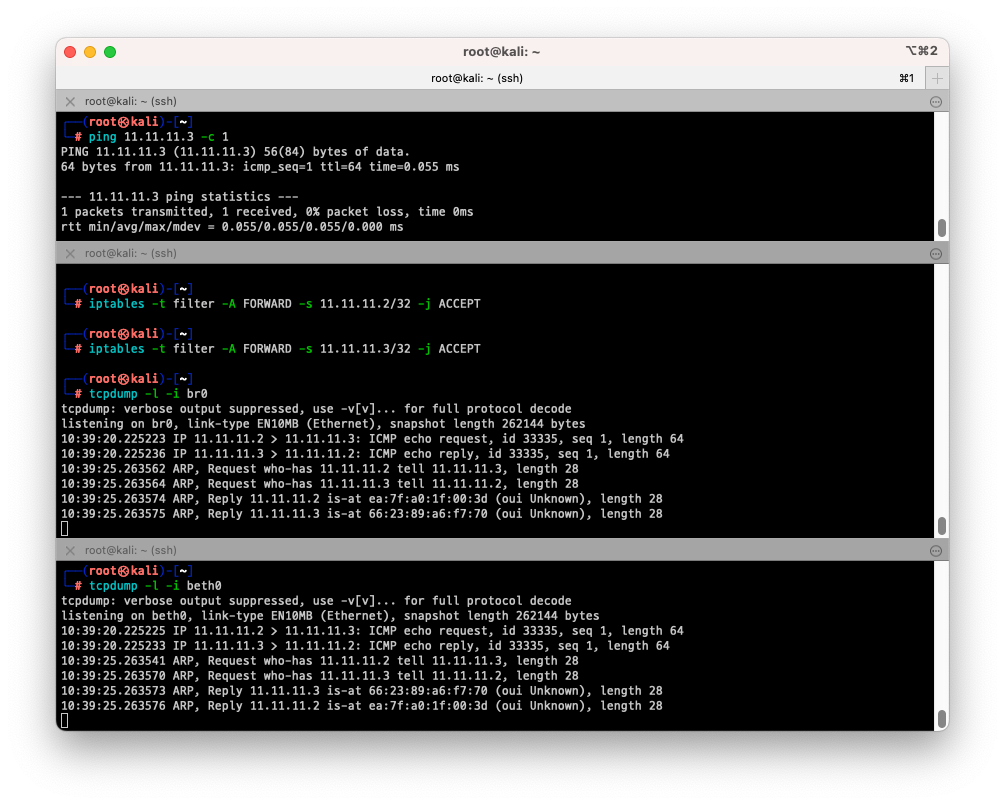
- 방법2. 도착지 11.11.11.0/24 대역 허용하기
# 터미널2 (호스트) $ iptables -t filter -A FORWARD -d 11.11.11.0/24 -j ACCEPT # 테스트 후 허용 룰 제거 $ iptables -t filter -D FORWARD -d 11.11.11.0/24 -j ACCEPT - 방법3. FORWARD 기본 정책을 ACCEPT로 변경하기
# 터미널2 (호스트) $ iptables -t filter -P FORWARD ACCEPT # 테스트 후 허용 룰 제거 $ iptables -t filter -P FORWARD DROP
호스트 <=> RED/BLUE 네트워크 네임스페이스로 접근하기
- “Red <- Bridge (br0) -> Blue 네트워크 네임스페이스 간 통신”을 실습한 환경에 이어서 실습해보겠습니다.
# 터미널1 (RED 11.11.11.2)
$ nsenter --net=/var/run/netns/RED
$ tcpdump -i any
# 터미널3를 호스트 네트워크로 변경합니다.
$ exit
$ ip netns identify $$
# => (공백)
$ tcpdump -i br0 -n
# 터미널2 (호스트)
$ ping -c 1 11.11.11.2
# => 1 packets transmitted, 0 received, 100% packet loss, time 0ms
# (ping 이 실패합니다.)
- 호스트에서 RED (11.11.11.2) 로 ping시 패킷이 전달되지 않는것을 확인할 수 있습니다.
- 그 이유는 RED 네트워크로 접근하기 위해서는 br0를 거쳐서 접근해야하는데, br0는 ip가 없기 때문에 패킷이 전달되지 않습니다.
- br0에 ip를 할당하고, RED와 BLUE 네트워크 네임스페이스로 접근해보겠습니다.
# 터미널2 (호스트)
$ ip addr add 11.11.11.1/24 dev br0
$ ip addr
# => ...
# 30: <span style="color:teal;">br0: </span><BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state <span style="color:green;">UP </span>group default qlen 1000
# link/ether <span style="color:olive;">7e:31:cf:5f:00:8f</span> brd <span style="color:olive;">ff:ff:ff:ff:ff:ff</span>
# inet <span style="color:purple;">11.11.11.1</span>/24 scope global br0
# valid_lft forever preferred_lft forever
$ ping 11.11.11.2 -c 1
# => PING 11.11.11.2 (11.11.11.2) 56(84) bytes of data.
# 64 bytes from 11.11.11.2: icmp_seq=1 ttl=64 time=0.044 ms
#
# --- 11.11.11.2 ping statistics ---
# 1 packets transmitted, 1 received, 0% packet loss, time 0ms
# rtt min/avg/max/mdev = 0.044/0.044/0.044/0.000 ms
$ ping 11.11.11.3 -c 1
# => PING 11.11.11.3 (11.11.11.3) 56(84) bytes of data.
# 64 bytes from 11.11.11.3: icmp_seq=1 ttl=64 time=0.052 ms
#
# --- 11.11.11.3 ping statistics ---
# 1 packets transmitted, 1 received, 0% packet loss, time 0ms
# rtt min/avg/max/mdev = 0.052/0.052/0.052/0.000 ms
- 이번에는 RED에서 호스트로 ping이 되는것을 확인해 보겠습니다.
# 터미널1 (RED 11.11.11.2)
# br0 에 ping 테스트
$ ping 11.11.11.1 -c 1
# => PING 11.11.11.1 (11.11.11.1) 56(84) bytes of data.
# 64 bytes from 11.11.11.1: icmp_seq=1 ttl=64 time=0.041 ms
#
# --- 11.11.11.1 ping statistics ---
# 1 packets transmitted, 1 received, 0% packet loss, time 0ms
# rtt min/avg/max/mdev = 0.041/0.041/0.041/0.000 ms
# 호스트로 ping 테스트
$ ping 10.10.10.51 -c 1
# => ping: connect: Network is unreachable
- br0에는 ping 이 성공하는데 호스트로는 Network is unreachable 에러가 발생하는것을 확인할 수 있습니다.
- 그 이유는 11.11.11.0/24에서 호스트 네트워크인 10.10.10.0/24로 패킷을 라우팅하는 정보가 없기 때문입니다.
- RED나 BLUE에서 호스트로 패킷을 전달하기 위해서는 br0를 통해야 하는데, RED와 BLUE에 기본 게이트웨이를 br0로 설정하여 테스트해보겠습니다.
# 터미널1 (RED 11.11.11.2)
$ ip route add default via 11.11.11.1
$ ip route
# => default via 11.11.11.1 dev reth0
# 11.11.11.0/24 dev reth0 proto kernel scope link src 11.11.11.2
$ ping 10.10.10.51 -c 1
# => PING 10.10.10.51 (10.10.10.51) 56(84) bytes of data.
# 64 bytes from 10.10.10.51: icmp_seq=1 ttl=64 time=0.041 ms
#
# --- 10.10.10.51 ping statistics ---
# 1 packets transmitted, 1 received, 0% packet loss, time 0ms
$ exit
# BLUE에서도 동일하게 테스트해보겠습니다
# 터미널1 (BLUE 11.11.11.3)
$ nsenter --net=/var/run/netns/BLUE
$ ip netns identify $$
# => BLUE
$ ping 10.10.10.51 -c 1
# => ping: connect: Network is unreachable
$ ip route add default via 11.11.11.1
$ ip route
# => default via 11.11.11.1 dev beth0
# 11.11.11.0/24 dev beth0 proto kernel scope link src 11.11.11.3
$ ping 10.10.10.51 -c 1
# => PING 10.10.10.51 (10.10.10.51) 56(84) bytes of data.
# 64 bytes from 10.10.10.51: icmp_seq=1 ttl=64 time=0.049 ms
#
# --- 10.10.10.51 ping statistics ---
# 1 packets transmitted, 1 received, 0% packet loss, time 0ms
# rtt min/avg/max/mdev = 0.049/0.049/0.049/0.000 ms
-
ip route add default via 11.11.11.1로 기본 게이트웨이를 br0로 설정하고, 호스트로 ping이 되는것을 확인할 수 있습니다.
RED/BLUE에서 외부 인터넷 통신
- 이번에는 RED와 BLUE 네트워크 네임스페이스에서 외부 인터넷으로 통신하는 방법을 실습해보겠습니다.
# 터미널1 (RED 11.11.11.2)
$ nsenter --net=/var/run/netns/RED
$ ping 8.8.8.8 -c 1
# => PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
#
# --- 8.8.8.8 ping statistics ---
# 1 packets transmitted, 0 received, 100% packet loss, time 0ms
- RED에서 외부 인터넷으로 ping이 되지 않는것을 확인할 수 있습니다.
- RED/BLUE와 같이 호스트 아래의 내부 네트워크에서 외부 인터넷으로 패킷을 전달하기 위해서는 호스트의 IP로 패킷을 전달하고, 응답을 호스트 IP로 받아서 내부 네트워크(RED/BLUE)로 전달해야하는데, 이러한 과정을 SNAT (Source Network Address Translation) 또는 MASQUERADE라고 합니다.
- nat 테이블의 POSTROUTING 체인에 MASQUERADE 룰을 추가하면 SNAT이 적용되어서 외부 인터넷으로 패킷을 전달할 수 있습니다.
# 터미널2 (호스트)
$ iptables -t nat -A POSTROUTING -s 11.11.11.0/24 -j MASQUERADE
# SNAT 통계 모니터링
$ watch -d 'iptables -v --numeric --table nat --list POSTROUTING'
$ iptables -nvL -t nat
$ conntrack -L --src-nat
# => icmp 1 29 src=11.11.11.2 dst=8.8.8.8 type=8 code=0 id=62779 src=8.8.8.8 dst=10.10.10.109 type=0 code=0 id=62779 mark=0 use=1
# conntrack v1.4.8 (conntrack-tools): 1 flow entries have been shown.
# 터미널1 (RED 11.11.11.2)
$ ping 8.8.8.8 -c 1
# => PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
# 64 bytes from 8.8.8.8: icmp_seq=1 ttl=113 time=26.3 ms
#
# --- 8.8.8.8 ping statistics ---
# 1 packets transmitted, 1 received, 0% packet loss, time 0ms
# rtt min/avg/max/mdev = 26.277/26.277/26.277/0.000 ms
$ exit
# 터미널1 (BLUE 11.11.11.3)
$ nsenter --net=/var/run/netns/BLUE
$ ip route add default via 11.11.11.1
$ ping 8.8.8.8 -c 1
$ exit
# 삭제
$ ip netns delete RED
$ ip netns delete BLUE
$ ip link delete br0
$ iptables -t nat -D POSTROUTING -s 11.11.11.0/24 -j MASQUERADE
- SNAT 추가한 이후 ping이 잘 되는것을 확인할 수 있었습니다.
마치며
첫주부터 이론과 실습할것이 굉장히 많았습니다. 테라폼 스터디가 순한맛으로 보일 정도입니다. 😅 하지만 그동안 막연하게 알고 있었던 도커 컨테이너의 격리 원리와 리눅스 네트워크와 iptables에 대해 더 깊게 이해할 수 있어서 좋았습니다.
개인적으로 *BSD를 좋아하는데 이 정도면 FreeBSD에서도 BSD만의 docker 같은 에코시스템 구축이 가능할것 같은데
왜 못하고 있는지 의문입니다. 비슷하게 돌릴 수 있는 다양한 시도들은 많은데 흐지부지 되는 이유는 대체 무엇인지..
항상 무언가를 배우는것은 즐겁습니다. 다음 스터디도 기대됩니다! ![]()